
베이즈추정법 : 모수 $\mu$ 의 신뢰도 분포를 나타내는 작업
- 핵심 아이디어 : 모수 = 확률변수
- 주어진 데이터를 기반으로 모수 $\mu$ 의 조건부확률분포 $p(\mu \vert x_{1}, x_{2}…x_{n})$ 을 계산하는 작업이다.
베이즈정리를 사용한다.
- 최대가능도추정법과의 연결점 : 가장 가능성 높은 모수를 ‘추정 모수’(추정 결과) 로 쓰겠다.
- 최대가능도추정법과의 차별점 :
1. 최대가능도추정법에서는 가장 가능도 높은 모수 $\mu$ 하나를 찾는 게 모든 관심사였다.
하지만 베이지안 추정법은 가장 가능성 높은 모수를 찾고, 찾은 모수가 얼마만큼의 추정 신뢰도와 신뢰구간에서 찾아진건지도 알 수 있다는 장점 있다.
즉 가장 가능성 높은 모수를 찾고, 이걸 ‘얼마만큼 믿을 수 있는가’에 대해서도 제시한다. MLE 방법과 비교했을 때 모수추정을 더 세밀하게 할 수 있는 것이다.
2. 새 데이터를 추가로 얻었을 때, 계산해둔 기존 결과에 추가된 것만 그대로 반영해서 업데이트된 결과물 얻을 수 있다.
최대가능도추정법의 경우 데이터 새로 얻으면 모든 데이터를 가지고 처음부터 다시 계산해야 한다.(번거롭다)
모수 $\mu$ 의 신뢰도 분포 나타내는 방법
- 모수적 방법 - 모수 $\mu$ 의 조건부확률분포를 다른 확률분포 빌려서 [직접] 표현하는 방법
- 비모수적 방법 - 모수 $\mu$ 의 조건부확률분포에서 직접 표본 추출해서, 히스토그램 그려서 [간접] 표현하는 방법
모수적 방법 - 다른 확률분포 빌려서 모수분포 직접 표현하기
- 모수분포는 베이즈 정리의 출력 모수 $\mu$ 의 조건부분포를 말한다.
$p(\mu \vert x_{1}, x_{2}…x_{n}) = p(x_{1}, x_{2}…\vert \mu)p(\mu)$
모수 $\mu$ 에 대한 별 다른 정보 없을 경우 사전분포 $p(\mu)$ 는 모수 a=1, b=1 인 베타분포 또는 기댓값이 0인 정규분포 등의 무정보분포(엔트로피가 가장 큰) 를 사용한다.
사전분포와 사후분포 분포 종류가 같으면, ‘켤레분포’ 또는 ‘켤레사전확률분포’라고 한다.
모수의 분포(사후분포)를 나타내는 다른 확률분포의 모수를 ‘하이퍼 모수’라고 한다. 모수적 방법은 이 ‘하이퍼 모수’를 계산하는 작업이다.
예를 들어 베르누이 확률변수 모수 $\mu$ 의 사후분포를 모수적 방법으로 나타낼 때, 사후분포의 하이퍼 모수는 다음처럼 계산할 수 있다.
$a’ = N_{1}+a$
$b’ = N_{0}+b$
갱신된 하이퍼 모수를 갖는 베타분포(사후분포)는 곧 모수 $\mu$ 의 신뢰도분포다.
예1 )
1
2
3
4
5
6
7
8
9
10
xx = np.linspace(0,1)
a0 = 1
b0 = 1 # 사전분포의 하이퍼모수
plt.plot(xx, sp.stats.beta(a0,b0).pdf(xx), ls=':', c='r', label='사전분포')
a1 = 60+1
b1 = 40+1 # 사후분포의 하이퍼모수
plt.plot(xx, sp.stats.beta(a1, b1).pdf(xx), ls='--', c='g', label='사후분포')
plt.legend()
plt.title('상품 B 모수 조건부 분포의 사전분포와 사후분포')

예2 )
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 실제 베르누이분포 모숫값 : 0.65
# 베이즈 추정법 사용한 모수추정을 해보자.
# 데이터 50개씩 추가해가면서 추정 결과를 업데이트하자.
mu0 = 0.65
a,b = 1,1
xx = np.linspace(0,1,10000)
plt.plot(xx, sp.stats.beta(a,b).pdf(xx), c='r',label='사전분포')
np.random.seed(0)
ls = [':', '--', '-.']
c = ['r', 'g', 'b']
for i in np.arange(3) :
sample = sp.stats.bernoulli(mu0).rvs(50)
n0, n1 = np.bincount(sample)[0], np.bincount(sample)[1]
a = n1 + a
b = n0 + b
plt.plot(xx, sp.stats.beta(a,b).pdf(xx), ls=ls[i], c=c[i], label=f'{i+1}번째 추정')
print(f'{i+1}차 추정 : 모드 = {(a-1)/(a+b-2)}')
plt.legend()
plt.title('데이터 50개씩 추가해가며 베이지안 추정결과 업데이트하기')
plt.xlabel('$\mu$')
plt.vlines(0.65, ymin=0, ymax=13, colors='k')
plt.show()

예3 )
베이즈추정법으로 정규분포 기댓값 모수 $\mu$ 추정하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 100개 씩 총 4번 데이터 얻어서 기댓값 모수를 추정해보자.
target_mu = 2
target_sigma2 = 4
mu = 0
sigma2 = 1
xx = np.linspace(1,3,10000)
plt.plot(xx, sp.stats.norm(mu, np.sqrt(sigma2)).pdf(xx), ls=':', c='b', label='사전분포')
ls = [':', '--', '-.', '-']
color= ['k', 'b', 'g', 'r']
np.random.seed(1)
for i in np.arange(4) :
sample = sp.stats.norm(target_mu, np.sqrt(target_sigma2)).rvs(100)
mu = target_sigma2/(100*sigma2+target_sigma2)*mu + 100*sigma2/(100*sigma2+target_sigma2)*np.mean(sample)
sigma2 = 1/(1/sigma2+100/target_sigma2)
plt.plot(xx, sp.stats.norm(loc=mu, scale=np.sqrt(sigma2)).pdf(xx), ls=ls[i], c=color[i], label=f'{i+1}번째 추정')
print(f'{i+1}번째 추정 모드 : mode = {mu}')
plt.legend()
plt.title(f'베이지안 추정법을 통한 정규분포 모수 $\mu$ 추정')
plt.vlines(target_mu, ymin=0, ymax=5)

예4 )
사이킷런 패키지 붓꽃 데이터 중 ‘꽃받침 길이’ 확률변수의 기댓값 모수 추정
- 꽃받침 길이 데이터들이 어떤 분포를 이루는지 보고, 이 데이터들이 어떤 분포에서 나왔는지 대강 짐작해보자.
1
2
3
4
5
from sklearn.datasets import load_iris
x = load_iris().data
df = pd.DataFrame(x, columns=load_iris().feature_names)
df[['sepal length (cm)']]

1
sns.distplot(df['sepal length (cm)'].values, kde=False, bins=50, fit=sp.stats.norm)

모양을 보니 정규분포에서 나온 데이터 일 수 있겠다.
정규분포에서 나온 데이터라고 가정하고, 베이즈추정으로 기댓값 모수를 추정해보자.
분산모수는 표본분산을 사용해서 안다고 가정한다.
- 모수 $\mu$ 가 정규분포 기댓값 모수이므로 $-\infty +\infty$ 사이 값일 것이다. 이외에 다른 정보는 주어진 게 없다. 따라서 기댓값 0인 무정보분포를 모수 $\mu$ 의 사전분포로 쓰자. 무정보분포의 분산 $\sigma^{2}$ 은 1이라 가정한다.
1
2
3
4
5
6
7
mu = 0
sigma2 = 1
xx = np.linspace(-5,5,10000)
plt.plot(xx, sp.stats.norm(mu, sigma2).pdf(xx))
plt.title(f'정규분포 기댓값 모수 $\mu$ 의 사전확률분포')
plt.show()

- 내가 가진 데이터를 반영한 사후분포의 하이퍼모수를 구한다. 그리고 기댓값 모수 $\mu$ 의 사후분포를 나타내자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
mu = 0
sigma2 = 1
xx = np.linspace(-3,8,10000)
plt.plot(xx, sp.stats.norm(mu, sigma2).pdf(xx), label='사전분포')
target_sigma2 = np.var(df['sepal length (cm)'].values, ddof=1)
data = df['sepal length (cm)'].values
mu1 = target_sigma2/(len(data)*mu+target_sigma2)*mu+len(data)*sigma2/(len(data)*sigma2+target_sigma2)*np.mean(data)
sigma21 = 1/(1/sigma2+len(data)/target_sigma2)
plt.plot(xx, sp.stats.norm(loc=mu1, scale=np.sqrt(sigma21)).pdf(xx), label='사후분포')
plt.legend()
plt.title('베이지안 추정으로 정규분포의 기댓값 모수 추정 결과')
print(f'추정된 정규분포 기댓값 모수 : {mu1}')
plt.show()

최종적으로 추정된 정규분포 기댓값 모수 : 5.81674331232002
모멘트방법으로 구한 기댓값 모수와의 비교
모멘트 방법에 따르면 표본평균은 이론적 기댓값과 같았다.
주어진 데이터를 이용해서 표본평균을 구하면 약 5.84가 나온다.
모멘트방법에 따라 이 5.84가 이론적 기댓값과 같다고 보면 5.84는 곧 정규분포의 기댓값 모수다.
내가 베이즈추정법으로 추정한 정규분포 기댓값 모수와 모멘트방법의 결과 5.84를 비교해보면, 약간의 차이가 있긴 하지만 두 방법 모두 비슷한 값을 모수로 추정해 낸 것을 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
plt.subplot(211)
sns.distplot(data, kde=False, fit=sp.stats.norm)
plt.title(f'표본분포 : 표본평균 이용해 구한 이론적 기댓값 = 5.84')
plt.vlines(5.84, ymin=0, ymax=1)
plt.ylim(0,1)
plt.xlim(4,8)
mu = 1
sigma2 = 1
xx = np.linspace(4,8,10000)
target_sigma2 = np.var(df['sepal length (cm)'].values, ddof=1)
data = df['sepal length (cm)'].values
mu1 = target_sigma2/(len(data)*mu+target_sigma2)*mu+len(data)*sigma2/(len(data)*sigma2+target_sigma2)*np.mean(data)
sigma21 = 1/(1/sigma2+len(data)/target_sigma2)
plt.subplot(212)
plt.vlines(5.84, ymin=0, ymax=6, colors='r')
plt.vlines(5.82, ymin=0, ymax=6, colors='b')
plt.plot(xx, sp.stats.norm(loc=mu1, scale=np.sqrt(sigma21)).pdf(xx))
plt.xlim(4,8)
plt.title(f'사후분포 : 베이즈추정법으로 구한 추정 기댓값 : 5.82')
plt.tight_layout()
plt.show()

검정 (testing) : 확률분포에 대한 가설이 맞는지 틀리는지 증명하는 작업
- 검정의 기본 전제 : 추정된 ‘추정값’은 ‘추정값’일 뿐이다!
추정 결과가 참인지, 거짓인지 판단할 여지가 남아있다!
예)
문) 동전을 15번 던졌는데 12번 앞면이 나왔다. 이 동전은 공정한 동전이라 할 수 있을까?
답) ‘동전 던지기 결과’는 베르누이확률변수라고 볼 수 있다.
베르누이확률변수의 모수는 $\mu$ 이다.
모수가 얼마일지, 추정해보자.
먼저 최대가능도추정법(MLE) 방법으로 베르누이확률변수의 모수를 추정해보자.
$\frac{N_{1}}{N}$
이다. 따라서 $\frac{12}{15}$ 가 베르누이확률변수의 모수 $\mu$ 라고 추정할 수 있다.
한편 베이즈추정법으로 모수를 추정해보자.
모수 $\mu$ 의 사후분포를 나타낼 하이퍼모수는 다음과 같이 계산할 수 있다.
$a’= N_{1} + a$ $b’= N_{0} + b$
하이퍼모수로 사후분포를 묘사, 모수를 추정하면 0.8로 나온다. 최대가능도 추정법 결과와 같았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 동전 15번 던져 12번 앞면 나왔다. 공정한 동전이라 할 수 있나?
# 베이즈 추정법으로 찾은 베르누이 확률변수 모수
a0 = 1
b0 = 1
a1 = 13
b1 = 4
xx = np.linspace(0,1,10000)
plt.plot(xx, sp.stats.beta(a0,b0).pdf(xx))
plt.plot(xx, sp.stats.beta(a1,b1).pdf(xx))
mode = 12/15
print(f'mode : {mode}')
plt.vlines(mode, ymin=0, ymax=4, color='r', ls=':')
plt.text(0.77, -0.2, 'mode')
plt.show()

그렇다면 모수추정 결과값은 0.8이라 할 수 있다. 이 0.8이 정말 모숫값이라면 이 동전은 ‘조작된 동전’일 것이다.
한편 0.8이 우연히 나온 결과에 불과하고, 실제 모수가 0.5라면 동전은 ‘공정한 동전’이라 말 할 수 있다.
이렇게 추정결과가 참인지 거짓인지 확인해 나가는 과정을 ‘검정’ 이라 한다.
- 가설(H) : 확률분포에 대한 주장
- 검정(testing) : 확률분포에 대한 가설이 맞는지, 틀리는지 증명하는 작업
- 모수검정 : 모수에 대한 가설이 맞는지 틀리는지 증명하는 과정
귀무가설 : 기준상태, 도전의 대상
- 정의 : 모수에 대한 가설
- 표기 : $H_{0}$
영 가설 이라고도 한다.
- 형태 : 반드시 ‘등식’ 꼴이어야 한다
‘모수 = 증명하려는 가설의 기준값 상수’
형태다.
대립가설 : 연구가설, 증명대상, 내가 증명하고 싶은 것
- 정의 : 내가 주장하려는 가설
- 표기 : $H_{a}$
언제나 귀무가설과 한 쌍(pair)를 이룬다.
- 귀무가설과 대립가설은 꼭 여집합 관계일 필요는 없다.
여집합 관계이면 귀무가설 거짓일 때, 자동으로 대립가설은 참이 된다.
한편 만약 여집합 관계가 아니라면 귀무가설이 거짓이라고 해서 자동으로 대립가설이 참 임이 증명되지 않는다.
따라서 여집합 관계가 아닐 때 대립가설이 참 임을 증명하려면 1. 귀무가설이 거짓임 2. 대립가설이 참임 1,2, 두 가지를 모두 증명해야 한다.
검정통계량
- 정의 : 귀무가설이 맞거나 틀렸다는 것을 증명할 ‘증거’
- t로 나타낸다.
- 확률변수 X에서 나온 표본데이터를 입력으로 받아 출력된 함숫값이다.
- 검정통계량 값도 표본데이터에의해 확률적 데이터가 나오는 확률변숫값이다. 따라서 검정통계량확률변수(분포) T 에서 나온 값이라고 본다.
*통계량 : 표본데이터를 하나의 공식에 넣어서 얻어낸 하나의 값
$\Leftarrow$ 확률변수 X 의 데이터로부터 어차피 X의 모수 추정하고 모수에 대한 가설(이 모수가 참인가? 거짓인가?)까지 세웠을 것이다.
$\Leftarrow$ 이 가설 증명하려면 이 데이터들을 검정통계량 값으로 바꾸면 된다.
$\Leftarrow$ 이 검정통계량 값은 확률변수 값으로써, 특정한 검정통계량분포에서 나온 값이다.
$\Leftarrow$ 내가 들고 있는 검정통계량 값이 검정통계량 분포 내에서 어디쯤 위치하는지 보고, 귀무가설 참. 거짓 유무 판단하면 된다.
자주 사용하는 검정통계량 & 검정통계량분포
베르누이분포 확률변수
- 베르누이확률변수의 모수에 대한 가설을 증명하려면 :
- 검정통계량 값 : N번 중 성공한 횟수 n 번
- 검정통계량이 따르는 분포 : 이항분포
$\sigma^{2}$ 모수를 아는 정규분포 확률변수
- 정규분포확률변수의 모수에 대한 가설을 증명하려면 :
- 검정통계량 값 : 표본평균을 정규화한 Z 통계량 값
- 검정통계량이 따르는 분포 : 표준정규분포
$\sigma^{2}$ 모수를 모르는 정규분포 확률변수
- 정규분포확률변수의 기댓값 모수 $\mu$ 에 대한 가설을 증명하려면 :
- 검정통계량 값 : 표본평균을 표본표준편차 s 로 정규화한 t 통계량 값
- 검정통계량이 따르는 분포 : 자유도 N-1 인 스튜던트 t 분포
- $\sigma^{2}$ 에 대한 가설을 증명하려면 :
- 검정통계량 값 : 표본분산 $s^{2}$ 을 정규화한 값
$t = (N-1) \frac{s^{2}}{\sigma^{2}}$
- 검정통계량이 따르는 분포 : 자유도 N-1인 카이제곱분포
유의확률 (p-value)
귀무가설이 진실이라면, 내가 손에 쥐고 있는 검정통계량 값은 검정통게량분포에서 흔하게, 잘 나오는 값일 것이다.
귀무가설이 거짓이라면, 검정통계량값은 검정통계량분포에서 나오기 어려운 값일 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
xx = np.linspace(-4,4,10000)
black = {'facecolor' : 'black'}
plt.subplot(121)
plt.title('나오기 쉬운 값이 나온 경우(귀무가설이 참)')
plt.plot(xx, sp.stats.norm().pdf(xx))
plt.annotate('실현된 검정통계량값 $t_{0}$', xy=[0.5,0],xytext=[1,0.05], arrowprops=black)
plt.scatter(0.5,0,30)
plt.subplot(122)
plt.title('나오기 어려운 값이 나온 경우(귀무가설이 거짓)')
plt.plot(xx, sp.stats.norm().pdf(xx))
plt.scatter(3,0,30)
plt.annotate('실현된 검정통계량값 $t_{0}$', xy=[3,0], xytext=[3,0.05], arrowprops=black)
plt.suptitle('실현된 검정통계량값과 검정통계량분포', y=1.1)
plt.tight_layout()
plt.show()

유의확률 (p-value)
- 정의 : 검정통계량분포의 표본값 1개가 주어졌을 때, 내가 들고 있는 표본값 또는 그 값보다 더 희귀한 값들이 나올 수 있는 확률
또는
귀무가설이 맞다고 할 때, 현재 검정통계량값 & 더 희귀한 값들(대립가설 옹호하는) 이 나올 확률
$p(t for H_{a}\vert H_{0})$
논리흐름)
유의확률이 작다 : 귀무가설이 참 이면 주어진 표본 & 이것보다 희귀한 놈들이 나올 가능성 매우 낮다
$\Rightarrow$ 주어진 표본이 나왔다는 건 귀무가설 참인데 매우 낮은 가능성으로 이 표본이 나왔거나, 또는 귀무가설이 거짓이란 말이다.
한편
유의확률이 크다 : 귀무가설이 참 일 때 주어진 표본 & 이것보다 희귀한 놈들이 나올 가능성 높다
$\Rightarrow$ 귀무가설이 참이면 내가 들고 있는 표본 같은 놈들이 자주 나온다.
$\Rightarrow$ 주어진 표본은 귀무가설을 기각할만한 증거가 못 된다.
유의확률은 누적분포함수 cdf 이용해서 구할 수 있다.
유의확률이 검정통계량분포의 양쪽 끝단 면적 구한 것과 같으면 ‘양측검정 유의확률’ 이라고 한다.
단측검정 유의확률
- 정의 : 한쪽방향 유의확률만 사용하는 것.
- 사용 : 대립가설이 부등식 형태일 때
- 모수가 특정값 $\theta_{0}$ 보다 크다는 걸 증명하고 싶으면 ‘우측검정 유의확률’을 써야 한다.
- 모수가 특정값 $\theta_{0}$ 보다 작다는 걸 증명하고 싶으면 ‘좌측검정 유의확률’을 써야 한다.
유의수준
- 정의 : ‘기준점’. 귀무가설을 기각할 지 채택할 지 판단하는 기준점이다.
- 종류 : 1%, 5%, 10% 유의수준
유의확률이 유의수준보다 작으면 - 귀무가설 기각, 대립가설 채택
유의확률이 유의수준보다 크면 - 귀무가설 채택
기각역 : 검정통계량분포에서 유의수준에 해당하는 검정통계량값(지점)
- 활용 :
유의수준만큼에 해당하는 기각역 계산
내가 얻은 검정통계량 값과 기각역 바로 비교 (지점-지점 비교)
귀무가설 기각 / 채택 여부 판단 가능
위에서 들었던 예를 통해 직접 검정해보자 - 1
- 동전던지기 결과는 베르누이확률변수다.
- 추정된 모수 값은 $\mu = 0.8$ 이었다.
1
2
3
4
5
6
plt.bar([0,1], sp.stats.bernoulli(0.8).pmf([0,1]))
plt.xticks([0,1])
plt.title('최대가능도추정법, 베이즈추정법으로 추정한 모수 : $\mu = 0.8$')
plt.suptitle('불공정한 동전인가?', y=1.1)
plt.ylim(0,1)
plt.show()
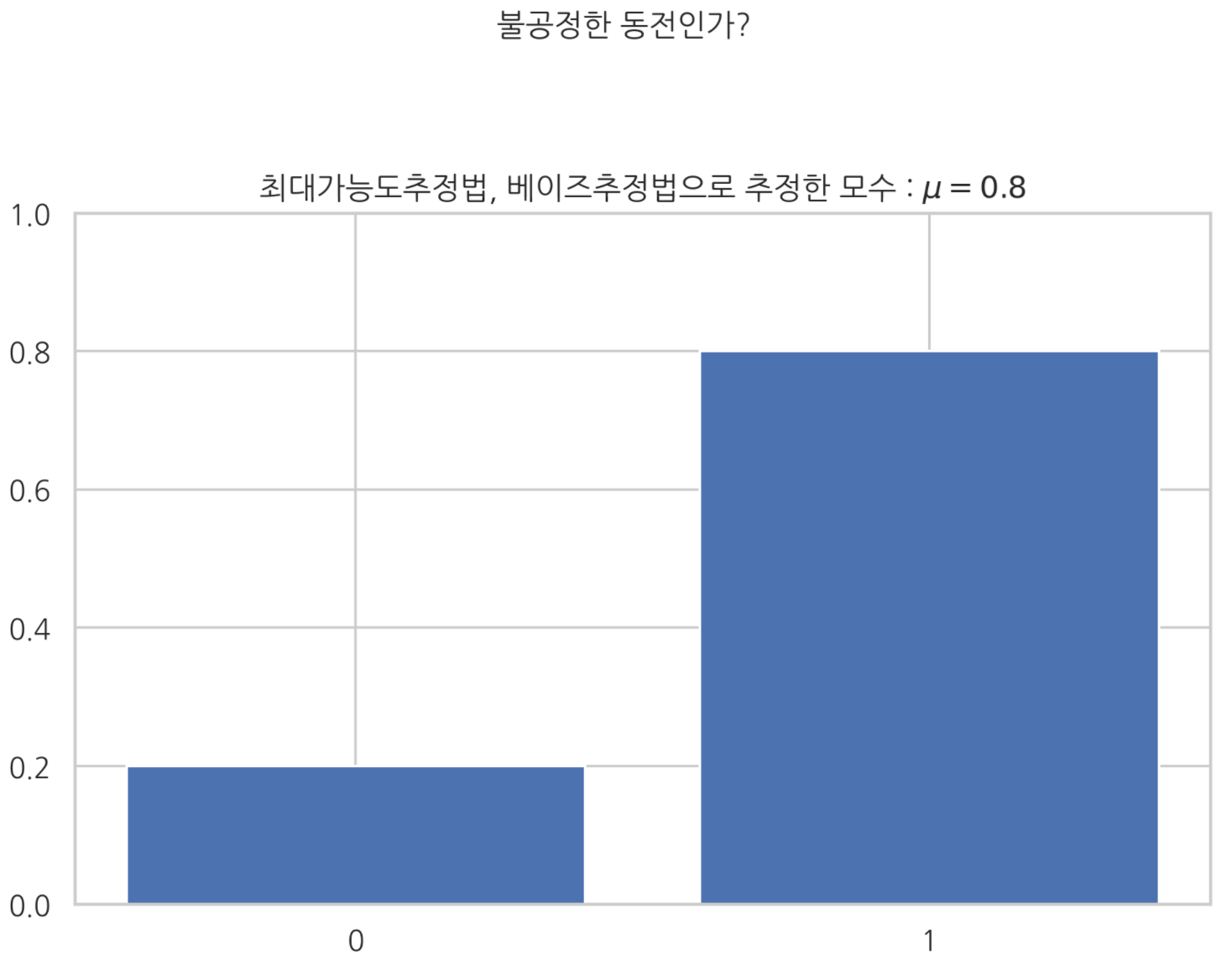
추정된 모수 $\mu = 0.8$ 만 보면 이 동전은 불공정한 동전같다.
이 동전이 불공정한 동전이다! 라는 주장을 그러면 검정해보자.
대립가설은 이렇게 세울 수 있다.
$H_{a} : \mu \ne 0.5$
그러면 귀무가설은 다음과 같다.
$H_{0} : \mu = 0.5$
이제 그러면 귀무가설(도전의 대상)이 참인지 거짓인지 증명해보자.
동전던지기 확률변수 X 는 베르누이확률변수였다. 베르누이확률변수 모수 $\mu$ 에 대한 가설을 증명하고 싶을 때, 검정통계량 값으로 이항분포의 표본값을 쓸 수 있고 검정통계량분포는 이항분포를 쓸 수 있었다.
검정통계량분포 기본 전제는 ‘귀무가설이 참이다($\mu = 0.5$)’ 였다.
- 검정통계량값 = 12
- 검정통계량분포 = 이항분포 $B(15, 0.5)$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
t = 12 # 검정통계량값
# 귀무가설을 따르는 검정통계량분포
N = 15
xx = np.arange(N+1)
black = {'facecolor' : 'black'}
plt.subplot(211)
plt.stem(xx, sp.stats.binom(N, 0.5).pmf(xx))
plt.title('동전 던지기 결과 베르누이분포의 검정통계량분포 : 이항분포 $B(15, 0.5)$')
plt.ylabel('pmf')
plt.annotate('실현된 검정통계량값 t=12', xy=[12,0.01], xytext=[12,0.05], arrowprops=black)
plt.subplot(212)
plt.stem(xx, sp.stats.binom(N, 0.5).cdf(xx))
plt.title('검정통계량분포의 누적분포함수')
plt.ylabel('cdf')
plt.tight_layout()
plt.show()

- 양측검정유의확률을 계산하면 다음과 같다.
$2(1-F(11))$
1
2
3
rv = sp.stats.binom(15, 0.5)
result = (1-rv.cdf(11))*2
print(f'양측검정 유의확률 : {np.round(result,3)}')
계산 결과는 약 3.5% 다.
유의수준 5%에서는 유의확률이 더 작으므로, 귀무가설 기각하고 대립가설 채택할 수 있다. 즉 ‘동전이 불공정한 동전이다’ 라는 주장이 참이다.
한편 유의수준 1% 에서는 유의확률이 더 크므로, 귀무가설 기각할 수 없다. ‘동전이 불공정한 동전이다’라고 말할 수 있는 증거가 부족하다.
예를 들어 직접 검정해보자 - 2
어떤 인터넷 쇼핑몰 상품 20개의 상품평이 있고, ‘좋아요’가 11개, ‘싫어요’가 9개다.
유의수준 10%에서 상품이 좋다는 주장을 검정해보자.
최대가능도 추정법으로 추정한 모수는 $\frac{11}{20}$ 이다.
베이즈추정법으로 추정해도 같다.
1
2
3
4
5
xx = np.linspace(0,1,10000)
plt.plot(xx, sp.stats.beta(12,10).pdf(xx))
print(11/20)
plt.vlines(11/20, ymin=0, ymax=4, colors='r')

모수추정 결과에 따르면 이 상품은 좋은 상품인 것 같다.
그러면 ‘이 상품이 좋은 상품이다!’라고 주장할 수 있을까?
내가 주장하고 싶은 바 : ‘상품이 좋은 상품이다’를 대립가설로 놓겠다.
$H_{a} : \mu > 0.5$
귀무가설은 그러면 다음과 같다.
$H_{0} : \mu = 0.5$
귀무가설이 참인지 거짓인지 증명하기 위해, 검정통계량값을 구해보자.
주어진 ‘상품평 확률변수’가 베르누이확률변수이므로, 검정통계량 t 값은 N번 중 성공횟수 n 이다.
$n = 11$
이 검정통계량 값은 검정통계량분포를 따른다. 이 분포는 이항분포 $B(20, 0.5)$ 이다.
이 검정통계량 값이 이항분포 상에서 어디 위치하는 지 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
mu0 = 0.5
N = 20
xx = np.arange(21)
plt.subplot(211)
plt.stem(xx, sp.stats.binom(N, mu0).pmf(xx))
plt.title('상품평 확률변수의 검정통계량분포 $B(20, 0.5)$')
plt.scatter(11, 0, 30, 'r')
plt.annotate('실현된 검정통계량 표본', xy=[11, 0], xytext=[11.5, 0.025], arrowprops=black)
plt.subplot(212)
plt.stem(xx, sp.stats.binom(N, mu0).cdf(xx))
plt.title('검정통계량분포의 누적분포함수')
plt.scatter(11,0, 30, 'r')
plt.tight_layout()
plt.show()

대립가설이 부등식이고 모수가 특정값보다 크다 를 증명하려 하므로, 우측검정 유의확률 사용하면 된다.
$1-F(10)$ 값 계산하면 된다.
계산하면,
1
2
rv = sp.stats.binom(N, mu0)
result = 1-rv.cdf(11-1)
약 0.411 (=41%) 이 나온다.
이 값은 유의수준 10% 보다 크다. 따라서 귀무가설 기각할 수 없다. 즉 상품이 좋다고 주장하기에는 증거가 부족하다.
메모
- 귀무가설-대립가설 설정에 깔려있는 stance :
대립가설 - 내가 주장.증명 하려는 바
여기에 대해 ‘의심’하고 ‘증명’을 요구한다. 증명 성공하기 전 까진 보수적 기조를 유지한다.
보수적 기조 : 귀무가설(도전의 대상)
검정 전 과정 내 언어로 요약.
- 모수추정을 통해 확률변수 X의 모수를 추정했다.
하지만 이 추정결과물은 ‘추정값’일 뿐, 정확한 모숫값이라고 말 못한다.
추정값이 참인가 거짓인가 따질 여지가 남아있다.
- 모수 추정값이 참인가, 거짓인가 따져보자.
나는 모숫값이 이번에 추정해 낸 바로 그 값이라고 주장하고 싶다.
이 추졍결과값을 가지고 대립가설($H_{a}$)을 세운다.
귀무가설은 최대한 보수적인 값으로 잡아둔다. 예) 가설의 기준이 되는 특정한 상수
내가 추정해낸 모숫값은 아직 확률변수 X의 모수라고 말 못하는 것이다.
따라서 확률변수 X의 확률분포 모수도 아직 귀무가설을 그대로 따른다.
- 귀무가설이 참인지 거짓인지 증명하자.
귀무가설 따르는 X 확률변수에서 얻어낸 표본데이터들을 가지고 검정통계량값 구한다.
검정통계량값이 따르는 검정통계량분포도 찾는다. 이 검정통계량분포 역시 귀무가설을 기본 전제로 따른다.
- 검정통계량값이 검정통계량분포에서 어디쯤 위치하는지 보고, ‘귀무가설이 참일 때, 현재 검정통계량 값 & 대립가설 더 옹호하는 값들이 나올 수 있는 확률=유의확률’을 계산한다.
‘귀무가설을 기각할 지, 채택할 지 판단하는 ‘기준점’ 인 유의수준과 유의확률을 비교한다.
유의수준보다 유의확률이 낮으면, 귀무가설 기각 / 유의수준보다 유의확률이 높으면 귀무가설 채택한다.
- 귀무가설이 기각되면 대립가설이 채택된다. 이 경우 내가 찾아낸 추정 결과값이 확률변수 X의 실제 모수를 잘 추정한 값이라고 믿을 수 있다.
반면에 귀무가설이 채택되면 대립가설이 기각된다. 이 경우, 내가 찾아낸 추정 결과값이 거짓임을 의미한다. 이 경우 데이터를 더 모아야 한다.