
‘프로그래머가 알아야 할 알고리즘 40’(임란 아마드 지음, 길벗 출판사) 을 통해 너비우선탐색, 깊이우선탐색, 비지도학습-클러스터링 알고리즘, 연관규칙마이닝-빈출 패턴 성장알고리즘을 공부. 복습하고나서, 그 내용을 내 언어로 바꾸어 기록한다.
그래프 알고리듬 - 2
그래프 순회
정의
그래프 탐색(검색) 방법.
원칙
모든 정점과 간선 단 한번씩만 방문한다.
종류
너비우선탐색(BFS)
깊이우선탐색(DFS)
너비우선탐색(BFS)
그래프에 계층이 있을 때; 그래프 형상이 트리일 때 가장 효율적인 탐색 알고리즘이다.
정의
루트노드에서 시작해서, 트리 레벨 별로 정점들 방문하는. 그래프 탐색 방법.
구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 그래프 표현한 인접 리스트
graph = {
'amin' : ['wasim', 'nick', 'mike'],
'wasim' : ['amin', 'imran'],
'nick' : ['amin'],
'mike' : ['amin'],
'imran' : ['wasim', 'faras'],
'faras' : ['imran']
}
# 너비우선탐색 구현
def bfs(graph, start) :
que = [start] # 방문해야 할 곳
visited = [] # 방문한 곳
while que :
n = que.pop(0)
if n not in visited :
visited.append(n)
for neighbor in graph[n] :
que.append(neighbor)
return visited
bfs(graph, 'amin')
[‘amin’, ‘wasim’, ‘nick’, ‘mike’, ‘imran’, ‘faras’]
깊이우선탐색(DFS)
정의
왼쪽부터 모든 경로 세로로 순차 탐색하는 알고리즘.
구현
1
2
3
4
5
6
7
8
9
10
11
12
# 깊이우선탐색 구현
def dfs(graph, node, visited = []) :
if len(visited) == 0 :
visited = []
if node not in visited :
visited.append(node)
for neighbor in graph[node] :
dfs(graph, neighbor, visited)
return visited
테스트 1
1
dfs(graph, 'amin')
[‘amin’, ‘wasim’, ‘imran’, ‘faras’, ‘nick’, ‘mike’]
테스트 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
graph2 = {
'2' : ['6', '3', '4', '5'],
'6' : ['2', '7','9', '12'],
'3' : ['2', '81'],
'4' : ['2', '27'],
'5' : ['2', '31', '51'],
'7' : ['6', '8'],
'9' : ['6', '11'],
'12' : ['6', '19'],
'81' : ['3'],
'27' : ['4', '29'],
'31' : ['5', '24'],
'51' : ['5'],
'8' : ['7'],
'11' : ['9'],
'19' : ['12'],
'29' : ['27', '1'],
'24' : ['31', '71'],
'1': ['29'],
'71' : ['24']
}
for n in dfs(graph2, '2') :
print(n, end=' ')
2 6 7 8 9 11 12 19 3 81 4 27 29 1 5 31 24 71 51
비지도 학습
정의
비정형 데이터를 정형 데이터로 변환하는 과정.
비지도 학습 알고리듬
클러스터링 알고리듬
비슷한 것끼리 묶기.
묶는 방법: 벡터 공간에서, 각 데이터포인트들의 ‘유사도’ 이용해서 비슷한 것끼리 묶는다.
벡터 간 유사도 종류
1. 유클리드 거리
정의: 두 벡터 점 사이 거리.
공식: $d(A, B) = \sqrt{\sum_{i=1}^{n}{(a_{i}-b_{i})^{2}}}$
2. 맨해튼 거리
정의: 두 벡터 점 사이 가장 긴 거리.
공식: $d(A, B) = \sum_{i=1}^{n}{\vert{a_{i}-b_{i}}\vert}$
3. 코사인 유사도
정의: 두 벡터(화살표) 사이 코사인 각도 값.
공식: $cos\theta = \frac{a^{T}b}{\vert\vert{a}\vert\vert \vert\vert{b}\vert\vert}$
- 차원 높아질 수록 코사인 유사도가 두 벡터 사이 유사도 구하는 데 좋다.
1. K-평균 클러스터링 알고리듬
정의
평균값 중심으로, 벡터들 군집화 하는 알고리듬.
과정
- 임의로 중심벡터 $n$ 개 설정한다. ($n$개 클러스터)
- 각 중심벡터와 유사도 높은(유클리드 거리가 가까운) 벡터들 군집화 한다.
- 각 $n$ 개 클러스터에 속한 벡터들 평균값으로 중심벡터 조정한다.
- 중심벡터가 더 이상 안 변할 때 까지 2와 3 과정 반복한다.
본래 K-평균 클러스터링 알고리즘 종료 조건은 ‘중심벡터가 더 이상 안 변할 것’ 이지만 다른 종료조건 설정할 수도 있다.
- 최대반복횟수 지정
- 최대실행시간 지정
구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from sklearn import cluster
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# k-평균 클러스터링에 사용할 임의 데이터 생성
dataset = pd.DataFrame({
'x' : [11,21,28, 17, 29, 33, 24, 45, 45, 52, 51, 52, 55, 53, 55, 61, 62, 70, 72, 10],
'y' : [39, 36, 30, 52, 53, 46, 55, 59, 63, 70, 66, 63, 58, 23, 14, 8, 18, 7, 24, 10]
})
# 클러스터 갯수 k 임의로 설정하기: 3
kmeans = cluster.KMeans(n_clusters=3)
# k-평균 클러스터링 실행
kmeans.fit(dataset)
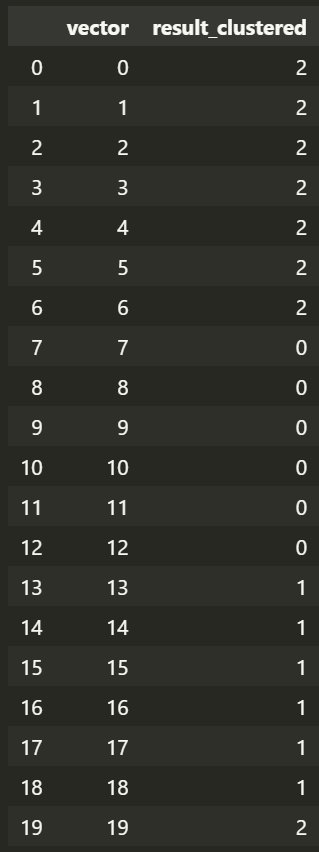
# 각 벡터 점이 어떤 클러스터로 '클러스터링' 되었나?
labels = kmeans.labels_
pd.DataFrame({
'vector' : list(range(20)),
'result_clustered' : labels
})
1
2
3
4
5
6
7
8
9
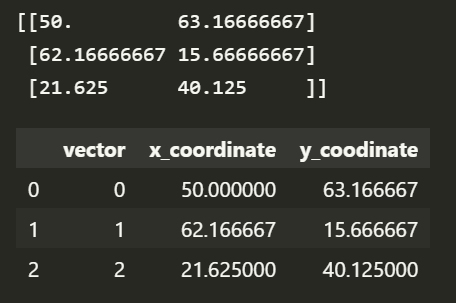
# 클러스터 별 중심점; 3개 중심점.
centers = kmeans.cluster_centers_
print(centers)
pd.DataFrame({
'vector' : list(range(3)),
'x_coordinate' : [centers[x][0] for x in range(3)],
'y_coodinate' : [centers[y][1] for y in range(3)]
})
1
2
3
4
5
6
7
8
9
# 클러스터 시각화
%matplotlib inline
plt.figure(figsize=(20,10))
plt.scatter(dataset['x'], dataset['y'], s=10)
plt.scatter([centers[x][0] for x in range(3)], [centers[y][1] for y in range(3)], s=100)
plt.title('K-means clustering result')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
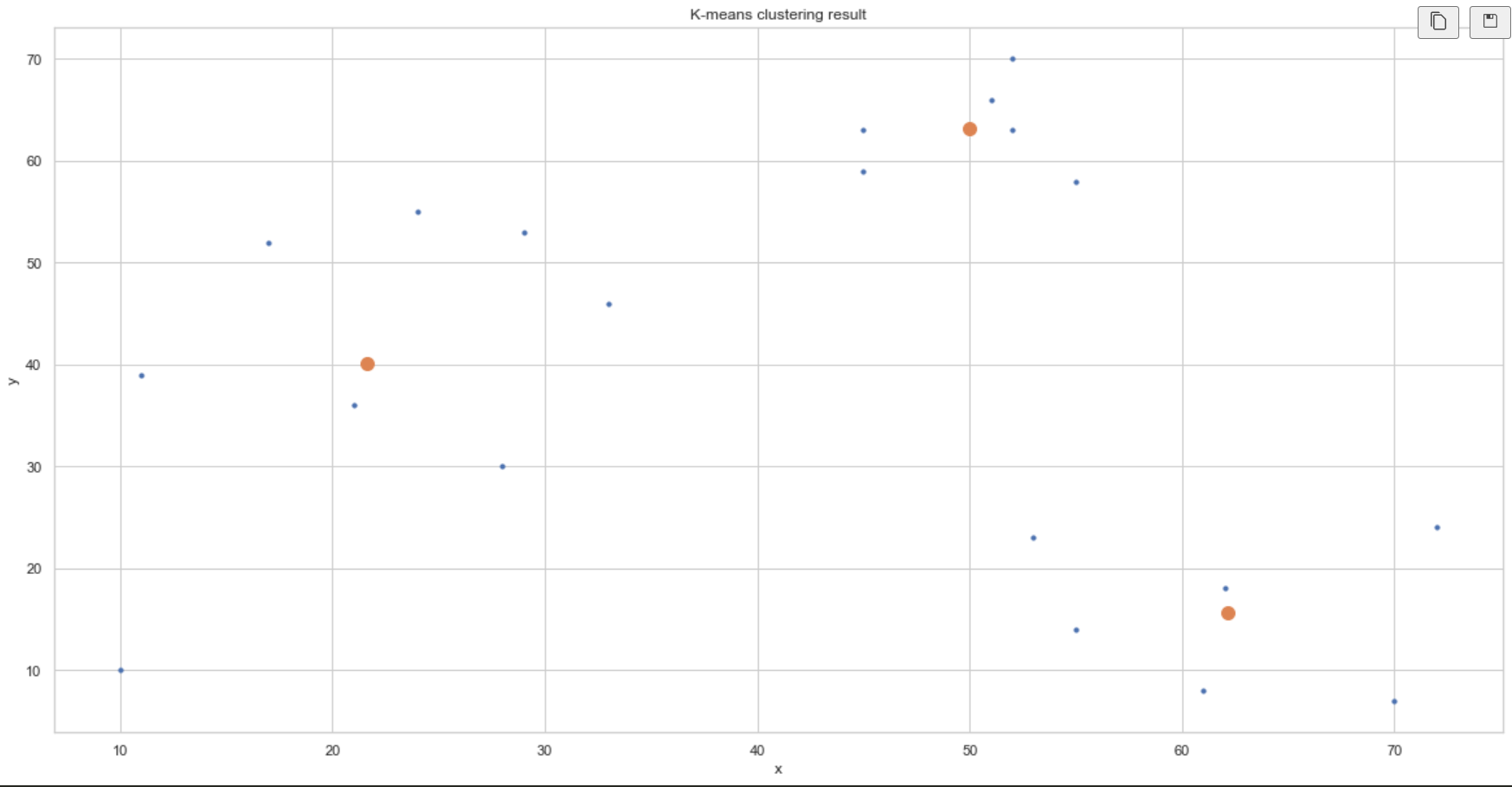
- 주황색은 중심벡터
한계
- 클러스터 갯수를 직접, 미리 지정해줘야 한다.
- 이상치에 약하다. 중심점이 벡터들 평균이므로, 중심점 조정할 때 마다 중심점이 아웃라이어에 질질 끌려 다닌다.
- 초창기 중심점 설정은 무작위 이므로, 알고리듬 실행할 때 마다 결과가 조금씩 달라질 수 있다.
- 각 데이터 포인트가 오직 1개 클러스터에만 할당된다.
2. 계층적 클러스터링 알고리듬
정의
전체 데이터포인트가 최종 1개 군집에 속할 때 까지, 비슷한 클러스터(데이터포인트) 끼리 클러스터링 하는 알고리듬.
k-평균 클러스터링 알고리듬과 비교했을 때, 장점: 임의로 $N$ 개 클러스터 지정 안 해도 된다.
과정
- 각각 데이터포인트를 1개 클러스터로 취급한다.
- 서로 거리 가장 가까운 클러스터 2개씩 묶는다.
*종료조건 임의로 지정해줄 수 있다; 예컨대, 클러스터가 3개 만들어졌을 때 종료. *계층적 클러스터링 결과로 나온 클러스터 구조를 ‘덴드로그램’ 이라고 한다.
구현
1
2
3
4
5
6
7
8
from sklearn.cluster import AgglomerativeClustering
# 임의 2차원 벡터 20개 생성
dataset = pd.DataFrame({
'x' : [11, 21, 28, 17, 29, 33, 24, 45, 45, 52, 51, 52, 55, 53, 55, 61, 62, 70, 72, 10],
'y' : [39, 36, 30, 52, 53, 46, 55, 59, 63, 70, 66, 63, 58, 23, 14, 8, 18, 7, 24, 10]
})
dataset

1
plt.scatter(dataset['x'], dataset['y'])
1
2
3
4
5
# 하이퍼파라미터 지정
# 개별 벡터 간 유사도: 벡터간 유클리드 거리로 측정. # 클러스터 간 거리 측정방식: 클러스터에 속한 벡터간 거리 평균
cluster = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='average')
cluster.fit_predict(dataset) # 20개 벡터에 대해 계층적 클러스터링 실행
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2, 2, 2, 1], dtype=int64)
1
print(cluster.labels_)
[0 0 0 0 0 0 0 0 0 0 0 0 0 2 2 2 2 2 2 1]
1
2
3
4
5
6
7
8
9
10
# 덴드로그램 시각화; 계층적 클러스터링 결과 시각화
from scipy.cluster.hierarchy import linkage, dendrogram
mergings = linkage(dataset, method='average')
# 덴드로그램 그리기
plt.figure(figsize=(4, 20))
dendrogram(mergings)
plt.show()
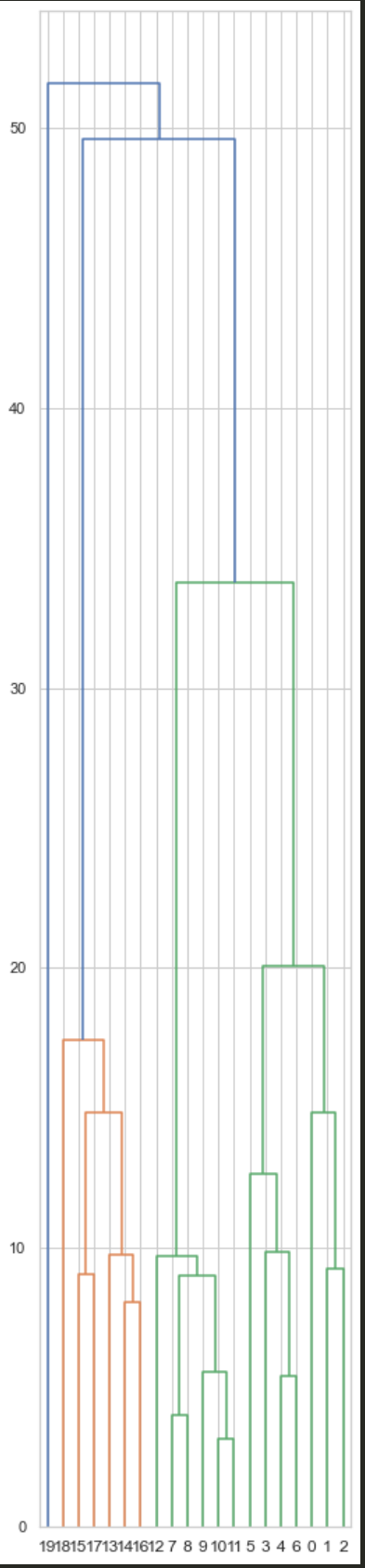
클러스터링 결과 품질 분석: 실루엣 분석
실루엣 분석
각 데이터포인트의 실루엣 계수 구하고, 실루엣 계수 이용해서 클러스터링이 잘 됬는지, 안 됬는지. 그 품질 분석한다.
실루엣 계수
정의
개별 데이터 포인트의 ‘군집도’.
- 같은 군집 내의 데이터들과 얼마나 가깝게 군집화 되어 있고, 다른 군집에 속한 데이터와는 얼마나 멀리 분리되어 있는지 동시에 나타내는 지표다.
- 실루엣 계수값이 1에 가까울 수록 근처 군집과는 멀리, 군집 내에서는 다른 점들과 가까이 위치한다는 뜻이다.
- 실루엣 계수값이 0에 가까울 수록 근처 군집과 가깝고, 군집 내에서 다른 점들과 멀다는 뜻이다.
- 실루엣 계수값이 -1에 가까우면 데이터 포인트가 아예 다른 군집에 잘못 클러스터링 되었음을 뜻한다.
‘잘 된 군집화’ 는 2가지 조건 만족해야 한다
- 전체 데이터 포인트에 대한 실루엣 계수 평균값(전체적으로 데이터가 클러스터링 잘 된 정도)이 1에 가까워야 한다.
- 전체 실루엣 계수 평균값과 각 개별 군집의 실루엣 계수 평균값 사이 편차가 크지 않아야 한다.
한편 개별 군집의 실루엣 계수 평균값이 0에 가까우면 다른 클러스터로 부터 제대로 떨어져 나오지 못한 군집, 1에 가까우면 확실히 분리된(clear-cut) 한 군집이다.
실루엣 분석 실행
1
2
3
4
5
# 클러스터링 결과 품질 평가 방법: 실루엣 분석
from sklearn.metrics import silhouette_samples, silhouette_score
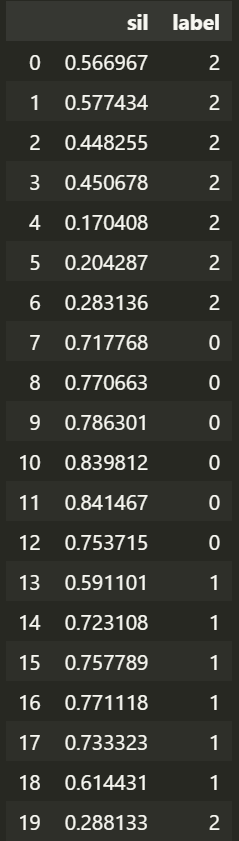
ss = silhouette_samples(dataset, labels);print(ss);print()
ss2 = silhouette_score(dataset, labels) ; print(ss2)
각 데이터포인트(벡터) 실루엣 계숫값
[0.56696738 0.57743412 0.44825528 0.45067759 0.17040846 0.20428702 0.28313587 0.7177684 0.77066252 0.78630094 0.83981177 0.84146727 0.75371487 0.59110102 0.7231076 0.75778881 0.77111825 0.73332291 0.61443136 0.288133 ]
전체 데이터포인트 실루엣 계숫값 평균
0.5944947210534494
클러스터 별 실루엣 계숫값 평균 및 전체 평균과 편차
1
2
3
4
clusterss = pd.DataFrame({
'sil' : ss,
'label' : labels
}) ;clusterss
1
2
3
4
5
6
7
8
9
10
11
12
13
14
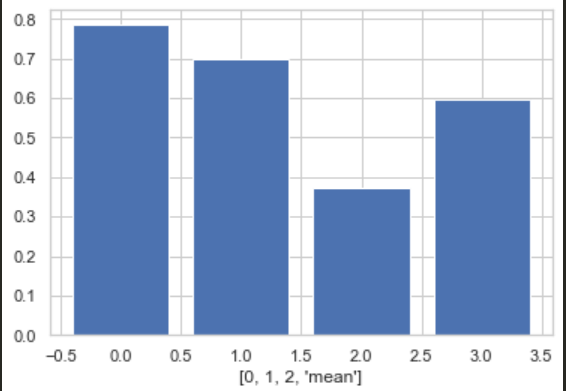
# 0 클러스터 실루엣 계수 평균
cluster_zero_mean = clusterss.query('label == 0')['sil'].values.mean() ; print(cluster_zero_mean)
# 1 클러스터 실루엣 계수 평균
cluster_zero_one = clusterss.query('label == 1')['sil'].values.mean() ; print(cluster_zero_one)
# 2 클러스터 실루엣 계수 평균
cluster_zero_two = clusterss.query('label == 2')['sil'].values.mean() ; print(cluster_zero_two)
print(f'실루엣 계수 전체 평균 : {ss2}')
plt.bar(range(4), [cluster_zero_mean, cluster_zero_one, cluster_zero_two, ss2])
plt.xlabel([0,1,2,'mean'])
plt.show()
0.7849542950490097
0.6984783222060621
0.37366233969231955
실루엣 계수 전체 평균 : 0.5944947210534494
연관규칙 마이닝
각 변수 사이 ‘연관관계’ 파악하기.
대표적 사례: 장바구니 분석. 장바구니 각 항목 간 연관관계 분석. (‘맥주와 기저귀’)
변수 간 연관규칙은 아래와 같이 표현한다.
${A, B} \Rightarrow {C}$
- 고객이 A, B를 함께 구입하면 C도 같이 사더라.
- 장바구니 분석에서, ${A, B}$, ${C}$ 는 $itemset$ 라고 한다. 말 그대로 고객이 구입한 물품 집합이다.
패턴, 연관규칙 평가 지표
- 지지도(support)
- 신뢰도(confidence)
- 향상도(lift)
1. 지지도(support)
정의
특정 패턴의 등장빈도.
공식
$support(itemset) = \frac{num_{transaction}}{total_{transaction}}$
- $num_{transaction}$: 전체 거래기록 중 특정 패턴($itemset$) 이 포함된 것 수
- $total_{transaction}$ : 전체 거래기록 갯수
2. 신뢰도(confidence)
정의
변수 $X$ 와 $Y$ 의 ‘연관도’.
변수 $X$ 가 $Y$ 로 이어질 확률 뜻한다.
예컨대 ${A,B} \Rightarrow {C}$, ${A,B} = X$, ${C}= Y$ , 연관관계의 신뢰도가 $70\%$ 이면.
소비자가 장바구니에 ${A,B}$ 담고 있으면 $70\%$ 확률로 ${C}$ 도 구매함을 뜻한다.
공식
$confidence(X\Rightarrow{Y}) = \frac{support(X Union Y)}{support(X)}$
3. 향상도(lift)
정의
연관규칙의 효용성 측정 지표.
- Y 구매 예측이 연관규칙 사용 안 할 때 보다 향상된 정도.
공식
$lift(X \Rightarrow Y) = \frac{support(X union Y)}{support(X) \times support(Y)}$
연관규칙 마이닝 알고리듬
1. Apriori 알고리듬
정의
가능한 모든 패턴($itemset$) 이용해서, 변수 간 연관규칙(관게) 찾는 알고리듬.
과정
- 전체 item 갯수가 $n$ 개 면. $2^{n}$ 개 패턴이 생성될 수 있다. 이 $2^{n}$ 개 패턴을 ‘후보패턴’으로 둔다.
- 모든 후보패턴에 대해서, 변수 간 연관규칙 찾고 그 신뢰도 계산한다. 일정 이하 신뢰도 갖는 연관규칙은 걸러낸다.
단점
item 갯수가 커질 수록, 후보패턴 갯수도 기하급수적으로 많아진다. 결국 후보패턴 생성 시간이 엄청나게 길어진다.
Apriori 알고리듬은 후보패턴 생성 못하면 그 다음 과정도 수행 못한다. 정리하면, item 갯수 많아질 수록 알고리듬 처리 시간이 엄청나게 지연된다.
2. FP-Growth 알고리듬
빈출 패턴 성장알고리듬.
정의
빈출패턴 집합 이용해서, 변수 간 연관규칙(관계) 찾는 알고리듬.
- Apriori 알고리듬이 가능한 모든 후보패턴 이용해서 연관규칙 찾았다면, FP-Growth 알고리듬은 FP 트리 이용해. 지지도 일정 이상인 빈출패턴만 찾고 이거 이용해서 변수 간 연관규칙 및 신뢰도 구한다.
특징 및 장점
Apriori 알고리듬의 item 갯수 많아질 수록 속도 느려지는 단점 보완한 알고리듬이다.
구현
1
2
3
4
5
6
7
8
9
10
11
12
# FP-Growth 알고리듬 구현
import pyfpgrowth as fp
dict2 = {
'id' : [0,1,2,3],
'items' : [['wickets', 'pads'],
['bat', 'wickets', 'pads', 'helmet'],
['helmet', 'ball'],
['bat', 'pads', 'helmet']]
}
transactionset = pd.DataFrame(dict2) ; transactionset

빈출패턴 찾기; 1 이상 빈도 가진 패턴만 남긴다.
1
patterns = fp.find_frequent_patterns(transactionset['items'], 1) ; patterns # 패턴 별 빈도 출력
{(‘ball’,): 1, (‘ball’, ‘helmet’): 1, (‘wickets’,): 2, (‘pads’, ‘wickets’): 2, (‘bat’, ‘wickets’): 1, (‘helmet’, ‘wickets’): 1, (‘bat’, ‘pads’, ‘wickets’): 1, (‘helmet’, ‘pads’, ‘wickets’): 1, (‘bat’, ‘helmet’, ‘wickets’): 1, (‘bat’, ‘helmet’, ‘pads’, ‘wickets’): 1, (‘bat’,): 2, (‘bat’, ‘helmet’): 2, (‘bat’, ‘pads’): 2, (‘bat’, ‘helmet’, ‘pads’): 2, (‘pads’,): 3, (‘helmet’,): 3, (‘helmet’, ‘pads’): 2}
빈출패턴으로부터 연관규칙 및 신뢰도 찾기
1
2
3
# 빈출패턴으로부터 연관규칙 및 신뢰도 찾기
rules = fp.generate_association_rules(patterns, 0.3) # 신뢰도 0.3 이상인 연관규칙만 생성
rules
{(‘ball’,): ((‘helmet’,), 1.0), (‘helmet’,): ((‘pads’,), 0.6666666666666666), (‘pads’,): ((‘helmet’,), 0.6666666666666666), (‘wickets’,): ((‘bat’, ‘helmet’, ‘pads’), 0.5), (‘bat’,): ((‘helmet’, ‘pads’), 1.0), (‘bat’, ‘pads’): ((‘helmet’,), 1.0), (‘bat’, ‘wickets’): ((‘helmet’, ‘pads’), 1.0), (‘pads’, ‘wickets’): ((‘bat’, ‘helmet’), 0.5), (‘helmet’, ‘pads’): ((‘bat’,), 1.0), (‘helmet’, ‘wickets’): ((‘bat’, ‘pads’), 1.0), (‘bat’, ‘helmet’): ((‘pads’,), 1.0), (‘bat’, ‘helmet’, ‘pads’): ((‘wickets’,), 0.5), (‘bat’, ‘helmet’, ‘wickets’): ((‘pads’,), 1.0), (‘bat’, ‘pads’, ‘wickets’): ((‘helmet’,), 1.0), (‘helmet’, ‘pads’, ‘wickets’): ((‘bat’,), 1.0)}