
‘프로그래머가 알아야 할 알고리즘 40’(임란 아마드 지음, 길벗 출판사) 을 통해 의사결정나무 알고리듬을 공부. 복습하고나서, 그 내용을 내 언어로 바꾸어 기록한다.
의사결정나무(Decision Tree)
정의
각 데이터포인트(레코드) 가장 잘 분류할 수 있는 특성변수와 기준점 찾고, 그 기준점에 따라 데이터포인트 분류하기.
$\Rightarrow$ 최적의 분류규칙 찾아서, 확률변수 Y의 분포 엔트로피 최소화 해 나가기.
과정
- 부모노드는 특정 레이블로 분류되는, 데이터포인트 집합을 갖는다. 부모노드를 확률변수 Y 라고 잡는다.
- 확률변수 Y가 갖는, 레이블 별 분포의 엔트로피 최소화 시키는, 특성변수와 기준점 찾는다. 즉, 조건 X(특성변수와 기준점) 에 대한 Y의 조건부 엔트로피 $H[Y\vert{X}]$ 가 최소화되는 X 찾는다. 또는 정보획득량(Information Gain: $H[Y]-H[Y\vert{X}]$)을 최대로 만드는 X 찾는다.
- 분류규칙보다 작은 데이터포인트들 vs 분류규칙보다 큰 데이터포인트들 로 데이터포인트를 이진분류한다.
- 이진분류된 데이터포인트들은 각각 부모노드의 왼쪽, 오른쪽 자식노드에 들어간다.
- 2에서 4 과정을 반복한다.
*루트노드에서 시작한다.
*‘가장 잘 분류할 수 있는 특성변수 & 기준점’을 ‘분류규칙’ 이라 한다.
*만약 자식노드에 분류된 데이터포인트의 클래스가 1개 뿐이면. 그 노드는 더 이상 나누지 않고 분기 종료한다.
예측
가장 마지막 이파리 노드에 담긴 데이터포인트 집합에서, 각 레이블에 속하는 데이터포인트 별 비율 구한다.
이 비율들을 조건부 확률분포로 본다.
$P(Y=k_{i}\vert{X}) \approx \frac{N_{k_{i}}}{N_{X}}$
$X =$ 가장 마지막 이파리노드에 담긴 데이터포인트 집합
$k_{i} =$ 레이블
$N_{X} =$ 데이터포인트 집합에 속한 데이터포인트 갯수
$N_{k_{i}} =$ 특정 레이블에 속한 데이터포인트 갯수
$\Rightarrow$ 예측값: $\hat{Y} = argmax_{k}(P(Y=k_{i}\vert{X}))$
분류문제 해결하기 - 1
붓꽃 분류문제
1
2
3
4
5
6
7
8
9
10
11
12
13
from sklearn.datasets import load_iris
data = load_iris()
y = data.target # 정답값(타겟값)들
x = data.data[:, 2:] # 입력데이터셋
feature_names = data.feature_names[2:]
# 의사결정나무 클래스
from sklearn.tree import DecisionTreeClassifier
# 분류기준 찾는 데 사용할 척도: 엔트로피, 의사결정나무 최대깊이:3
tree1 = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=0).fit(x, y)
특성변수는 ‘petal length (cm)’, ‘petal width (cm)’ 두 가지만 사용한다.
혼동행렬로 모델 분류 결과 파악하기
1
2
3
from sklearn.metrics import confusion_matrix
confusion_matrix(y, tree1.predict(x))
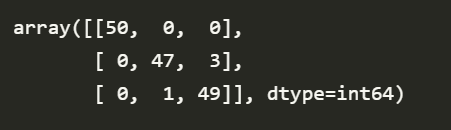
혼동행렬 의미는 다음과 같다.
행: 0,1,2 / 열: 0,1,2.
(1,1) 의 50은 실제 레이블 0인데 0으로 분류한 것 갯수다.
(2,2) 의 47은 실제 레이블 1인데 1로 분류한 것 갯수다.
(2,3) 의 3은 실제 레이블 1인데 2로 분류한 것 갯수다.(오분류)
나머지 1과 49도 위 논리로 읽으면 된다.
한편, 혼동행렬 뿐 아니라 각종 모델 성능 측정지표도 출력할 수 있다.
1
2
3
4
5
# 의사결정나무 모델 성능평가 지표
from sklearn.metrics import classification_report
print('훈련데이터에 대한 모델 성능평가')
print(classification_report(y, tree1.predict(x)))
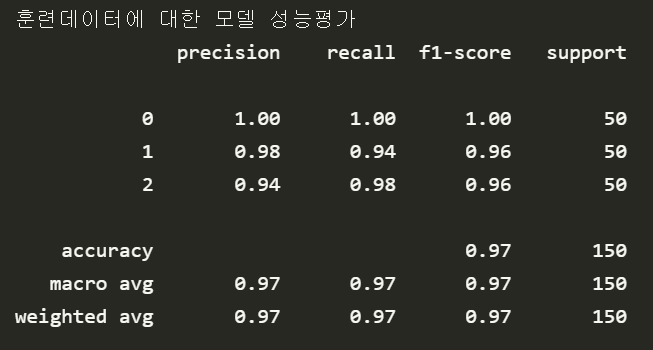
모델 분류결과의 정밀도, 재현율, F1 점수, 빈도, 정확도 등 나타낸다.
전체적으로 모델이 0.97 의 분류 정확도 기록했다.
의사결정나무 모델 시각화
1
2
3
4
5
from sklearn.tree import plot_tree
plt.figure(figsize=(100,50), max_depth=3)
plot_tree(tree1)
plt.show()

예컨대 가장 첫번째 노드를 보자.
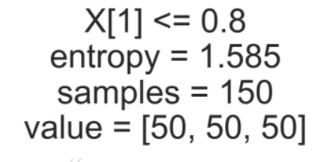
위에서 부터 순서대로,
- 확률변수 Y 의 조건부확률분포 엔트로피 최소화 시키는, 특성변수 & 기준점(0.8). 이 기준 갖고 각 데이터포인트(레코드) 왼쪽과 오른쪽 자식노드에 나눈다.
- 확률변수 Y 조건부확률분포의 엔트로피. 이 노드의 조건부확률분포는 value = $[50,50,50]$ 이다. 이 분포의 엔트로피 = 1.585
- 이 노드가 갖고 있는 총 데이터포인트 갯수. 이 노드는 150개 데이터포인트 갖고 있다.
- 확률변수 Y 의 조건부확률분포.
한편 가장 마지막 이파리 노드 중 하나를 보자.
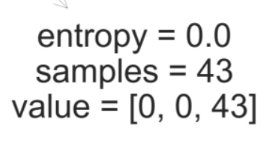
이 노드는 43개, 클래스 2인 데이터포인트들만 갖고 있다.
데이터포인트들의 클래스가 1개 뿐이므로 분기를 종료한다.
한편, value 조건부확률분포에서, 클래스 0의 조건부확률 값은 0, 1의 조건부확률값 0, 클래스 2의 조건부확률값 1 이므로
클래스 2의 조건부확률값이 가장 크다. 따라서 이 경우, 데이터포인트를 2로 분류(예측)한다.
분류문제 해결하기 - 2
타이타닉 분류문제 (생존 or 사망 이진분류문제)
1
2
3
4
5
# 타이타닉호 생존자 예측 연습문제
# 타이타닉 데이터셋 로드
df = sns.load_dataset('titanic')
df.head()

1
2
3
4
5
# pclass, age, sex 3 가지 특징변수만 사용할 거다.
feature_names = ['pclass', 'age', 'sex']
dfx = df[feature_names].copy()
dfy = df['survived'].copy()
dfx.head() # 훈련용 데이터셋
1
2
3
4
from sklearn.preprocessing import LabelEncoder
dfx['sex'] = LabelEncoder().fit_transform(dfx['sex']) # 성별 특징변수 값 --> 0과 1로 변환
dfx.tail()
1
2
dfx['age'].fillna(dfx['age'].mean(), inplace=True) # age 특징변수 null 값 전부 나이 평균값으로 대체해넣기
dfx.isnull().sum()
pclass 0
age 0
sex 0
dtype: int64
1
2
3
4
5
6
from sklearn.preprocessing import LabelBinarizer
dfx2 = pd.DataFrame(LabelBinarizer().fit_transform(dfx['pclass']), columns=['c1', 'c2', 'c3'], index=dfx.index) # 카테고리 변수인 pclass 특징변수 원핫인코딩 벡터 꼴로 변환
dfx = pd.concat([dfx, dfx2], axis=1);dfx
del(dfx['pclass'])
dfx.tail()
1
2
3
4
5
6
7
8
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
x_train, x_test, y_train, y_test = train_test_split(dfx, dfy, test_size=0.25, random_state=0) # 훈련용데이터 75, 테스트데이터 25 로 전체 데이터 분할
model = DecisionTreeClassifier(criterion='entropy', min_samples_leaf=5, max_depth=100).fit(x_train, y_train) # 의사결정나무 모델 정의 후 훈련
confusion_matrix(y_train, model.predict(x_train)) # 혼동행렬로 분류결과 확인
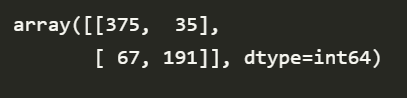
1
2
3
4
# 의사결정나무 분류결과 시각화
plt.figure(figsize=(100,50))
plot_tree(model)
plt.show()
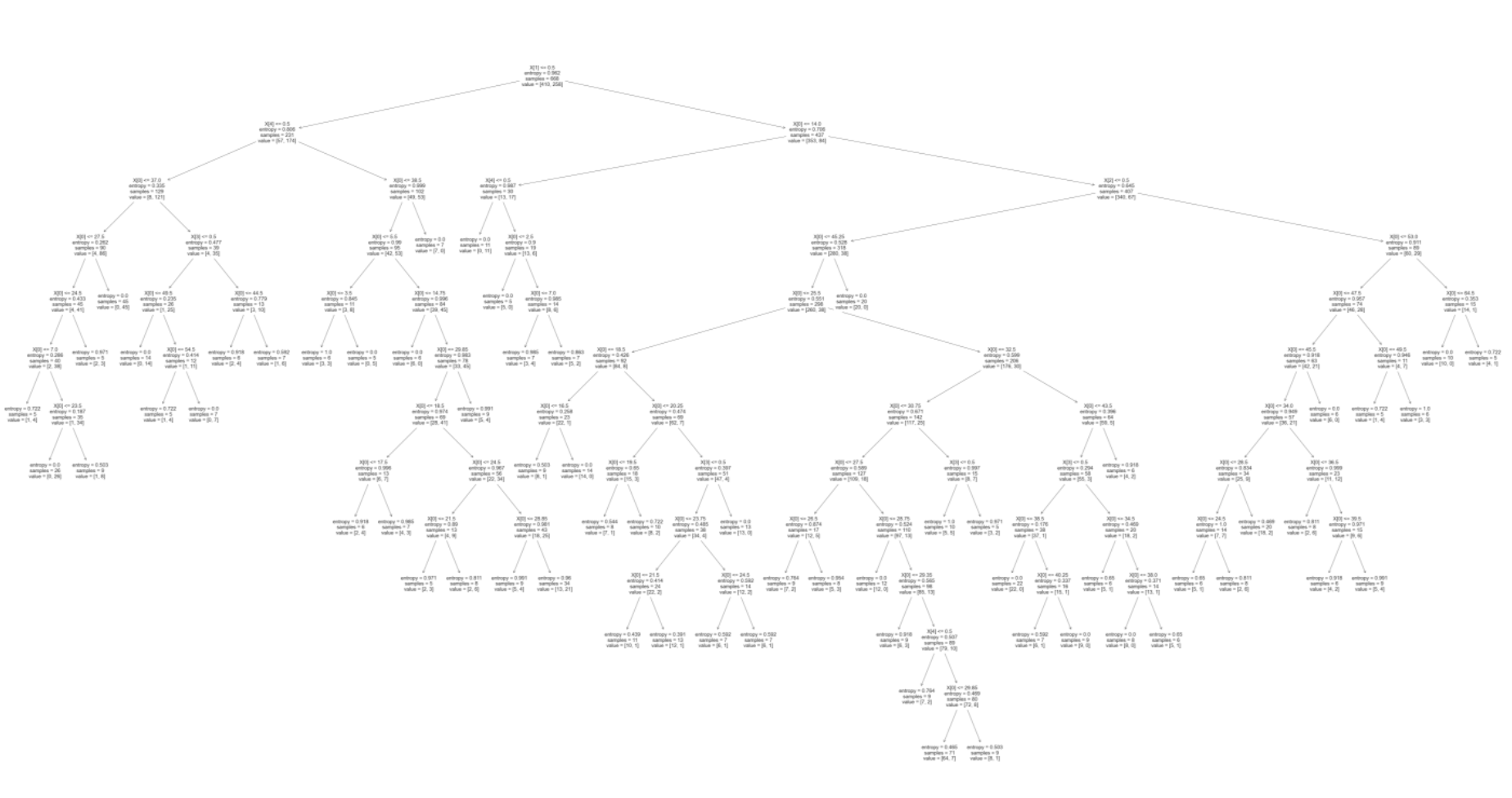
의사결정나무 장점
분류 과정과 결과를 쉽게 ‘설명가능’하다. 이렇게 분류결과를 설명할 수 있는 모델들을 화이트박스 모델 이라고도 한다.
의사결정나무 단점
- 트리 깊이가 너무 깊어지면, 모델이 훈련데이터에 과적합 될 수 있다.
- 의사결정나무는 탐욕 알고리즘의 일종이기 때문에, 매 순간 선택한 분류기준이 전체 관점에서는 최적 분류기준이 아닐 수 있다.