
아래 내용은 ‘케라스 창시자에게 배우는 딥러닝 (프랑소와 슐레 저, 박해선 옮김, 길벗 출판사)’ 을 공부한 뒤, 배운 내용을 제 언어로 정리.기록한 것 입니다.
신경망 기본 개념
신경망은 여러 겹의 ‘층(Layer)’ 으로 이루어져 있다.
각 층은 데이터 특징 추출 ‘필터’ 이다.
- 각 층은 함수로 생각할 수도 있다.
신경망은 여러 겹 필터로 구성된 ‘여과기’ 이다.
텐서(tensor)
머신러닝 기본 입력 데이터는 ‘텐서’다.
텐서
정의: 넘파이 다차원 배열
텐서 종류
스칼라(0차원 텐서)
숫자 하나 하나가 스칼라다. 스칼라는 0차원 텐서다.
1
2
3
4
# 스칼라 예
s = np.array(3)
s.ndim
0
벡터(1차원 텐서)
스칼라의 모임, 벡터가 1차원 텐서다.
1
2
3
4
5
6
7
# 벡터 (1차원 텐서) 예
v = np.array([1,2,3])
# or
v = np.array([[1],[2],[3]])
위 두 방식 모두 3차원 열벡터 나타내고, 동시에 1차원 텐서다.
행렬(2차원 텐서)
열벡터를 행벡터로 쌓은, 벡터의 모임. 행렬이 2차원 텐서다.
1
2
3
4
5
6
# 행렬(2차원 텐서) 예
np.array([
[1,2,3],
[4,5,6],
[7,8,9]])
3차원 텐서 및 고차원 텐서
행렬을 3차원으로 여러 개 쌓으면 3차원 텐서가 된다.
그리고 3차원 텐서 여러 개를 다시 여러 개 묶으면 4차원 텐서가 된다.
그 이상 차원을 가진 텐서도 가능하다.
보통 이미지 1개가 RGB 3개 채널(행렬)로 이루어진 3차원 텐서다.
$\Rightarrow$ 여러 이미지 묶음은 4차원 텐서가 될 것이다.
$\Rightarrow$ 1개 비디오는 여러 이미지 묶음(여러 프레임의 연속) 이므로 4차원 텐서가 된다. 여러 비디오를 묶어놓은 데이터셋은 5차원 텐서가 된다.
배치(batch) 데이터
1개 배치(batch) 는 여러 개 개별 데이터로 구성된 데이터 묶음이다.
예를 들어 배치 크기(batch size) 가 128 이라면, 1개 배치(묶음)에 128개 개별 데이터가 들어가 있다는 소리다.
벡터 브로드캐스팅
벡터 - 스칼라 연산을 할 때 스칼라를 1벡터 이용해 ‘브로드캐스팅’ 할 수 있었다. 그리고 그 결과, 벡터 - 스칼라 연산을 수행할 수 있었다.
한편 행렬 - 벡터 사이 벡터 브로드캐스팅도 가능하다.
예컨대 행렬 A
1
2
3
4
5
A = np.array([
[1,2,3],
[4,5,6],
[7,8,9]
])
와 벡터 B
1
2
3
4
5
B = np.array([
[1],
[2],
[3]
])
이 있다고 하자.
$A+B$ 연산을 수행하고 싶다.
이때, 벡터 B를 아래와 같이 브로드캐스팅 할 수 있다.
1
2
3
4
5
6
# 벡터 B를 브로드캐스팅해 만든 행렬
B = np.array([
[1,2,3],
[1,2,3],
[1,2,3]
])
이후 행렬 $A$ 와 $B$ 를 요소별 연산 $A+B$ 하면 된다.
1
2
3
4
5
6
# 요소별 연산 결과
result = np.array([
[2,4,6],
[5,7,9],
[8,10,12]
])
케라스 Sequential() 모델 이용해 MNIST 데이터 분류하기
데이터셋 로드
1
2
# mnist 데이터셋 로드
from keras.datasets import mnist
데이터셋을 훈련용 데이터셋과 검정용 데이터셋으로 분리
1
2
3
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
print(train_images.shape)
(60000, 28, 28)
train_images 는 3차원 텐서 데이터다.
6만개 28*28 행렬(2차원 텐서)로 구성되어 있다.
1
2
3
# GPU 확인
import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
Num GPUs Available: 1
1
print(test_images.shape);print(len(test_labels));print(test_labels)
(10000, 28, 28)
10000
[7 2 1 … 4 5 6]
- 검정용 test_images 데이터는 1만 개 28*28 행렬로 구성된 3차원 텐서다.
- test_labels 레이블 데이터(정답값)는 1만개 값으로 되어 있다. 각 값은 0~9 이다.
모델 로드
1
2
3
4
5
6
7
# 신경망 구조
from keras import models
from keras import layers
network = models.Sequential() # sequantial 모델 객체
network.add(layers.Dense(512, activation='relu', input_shape=(28*28,))) # 이미지 특징 추출 층
network.add(layers.Dense(10, activation='softmax')) # 1번 레이어에서 추출된 특징 소프트맥스 함수 이용해 확률 꼴로 바꾸는 층
모델 로드하고 2개 층을 구성했다. 1층은 렐루함수 이용해 이미지 특징 추출하는 층. 2층은 소프트맥스 함수 이용해 1층에서 나온 결과값들을 0과 1 사이, 총합 1 되는 ‘확률 꼴’ 로 바꾸는 층이다. 벡터로 출력된다.
모델 컴파일(훈련준비)
모델 훈련준비 시키는 과정을 ‘모델 컴파일’ 이라고 한다.
1
2
3
4
# 모델 컴파일(훈련준비)
network.compile(optimizer='rmsprop',# 최적화 방법
loss='categorical_crossentropy', # 손실함수(성능함수)
metrics=['accuracy']) # 모델 정확도 측정 방법
- 최적화 방법으로 rmsprop 방법을 적용했다.
- 손실함수(손실) 계산 방법으로 범주형 크로스엔트로피를 적용했다. 정답값(레이블)을 0과 1만으로 구성된 원핫 인코딩 벡터 꼴로 변환해 줄 것이다. 특정 이미지를 신경망에 통과시키고 나서 나오는 소프트맥스 함수 출력값들은 각 카테고리값에 대한 확률 꼴일 것이다. 소프트맥스 함수 출력값과 레이블의 원핫인코딩 벡터를 각각 확률분포라 생각할 수 있다. 이때 정답값 분포와 소프트맥스 함수 출력값 분포 사이 크로스엔트로피 값은 두 분포가 다른 정도를 나타내는 쿨백-라이블러 발산값과 같아진다. 여기서 쿨백-라이블러 발산값 또는 ‘두 분포가 다른 정도’가 예측 오차 또는 손실이 될 것이다.
- 모델 정확도 측정 방법으로 accuracy rate 를 적용했다. 곧, 정확하게 분류한 비율을 뜻한다.
입력 데이터 전처리
이미지 데이터는 일반적으로 신경망에 넣을 때 0과 1사이 값으로 크기 변환해서 넣는다.
1
2
3
4
5
6
7
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32')/255 # train 데이터 자료형을 실수형으로 바꾸고, 255로 나눠서 크기 조정 (0과 1사이 값들로 크기 조정)
test_images = test_images.reshape((10000, 28*28))
test_images = test_images.astype('float32')/255 # test 데이터 자료형을 실수형으로 변경 하고 255로 나눠서 크기 조정 (0과 1사이 값)
# 보통 신경망에 이미지 넣을 때는 0과 1사이 값으로 바꿔서 넣는다.
- 3차원 텐서였던 train_images 데이터셋(훈련용 데이터셋)을 $(60000,784)$ 크기 행렬로 변환한다. 여기서 주목할 점은, 개별 이미지는 $(1,784)$ 크기 행벡터가 되어 행렬을 구성하게 되었다는 점이다.
- 이후 행렬 각 원소를 부동소수점 실수 자료형인 float32 타입으로 바꾸고, 모든 값을 255로 나눠서 크기가 0과 1사이가 되게 조정했다.
- 한편 역시 3차원 텐서였던 test_images 데이터셋(검정용 데이터셋)을 $(10000, 784)$ 크기 행렬로 변환한다. 역시 개별 이미지는 $(1,784)$ 크기 행벡터가 되었다.
- 행렬 각 원소를 float32 타입으로 변환하고, 255로 나눠 크기를 0과 1사이로 조정한다.
1
2
3
4
5
6
# 레이블값 (정답 값) 모두 원핫인코딩 벡터 꼴로 변환
import keras.utils
train_labels = tf.keras.utils.to_categorical(train_labels) # 훈련용 데이터 정답값
test_labels = tf.keras.utils.to_categorical(test_labels) # 테스트 데이터 정답값
한편, 훈련용 데이터셋과 검정용 데이터셋의 레이블 데이터를 모두 원핫인코딩 벡터 꼴로 바꾼다.
변환 방법은 위와 같다.
변환 후 0~9 사이 각 레이블값들은 모두 0과 1로만 구성된 원핫 인코딩 벡터로 바뀌었다.
이렇게 입력데이터 전처리를 마친다.
1
2
# 전처리된 입력 데이터 크기 확인
train_images.shape
(60000, 784)
1
train_labels.shape
(60000, 10)
모델 훈련시키기
1
2
3
# 컴파일 된 모델 훈련데이터로 지도학습 하기
network.fit(train_images, train_labels, epochs=5, batch_size=128) # batch_size: 한번에 몇 개씩 예측.평가해서 가중치 업데이트 할 건가.

M1 맥의 GPU를 이용했다.
에포크는 5번, 배치 크기는 128을 설정했다.
- 모델을 훈련(학습) 시키는 작업 = 최적의 가중치(파라미터)를 찾는 작업 으로 정의할 수 있다.
- 모델 가중치는 학습 결과이자 모델에 저장된 정보다.
모델 성능 교차검증하기
1
2
# 모델에 테스트셋 넣어서 성증 교차검증 하기
test_loss, test_acc = network.evaluate(test_images, test_labels)
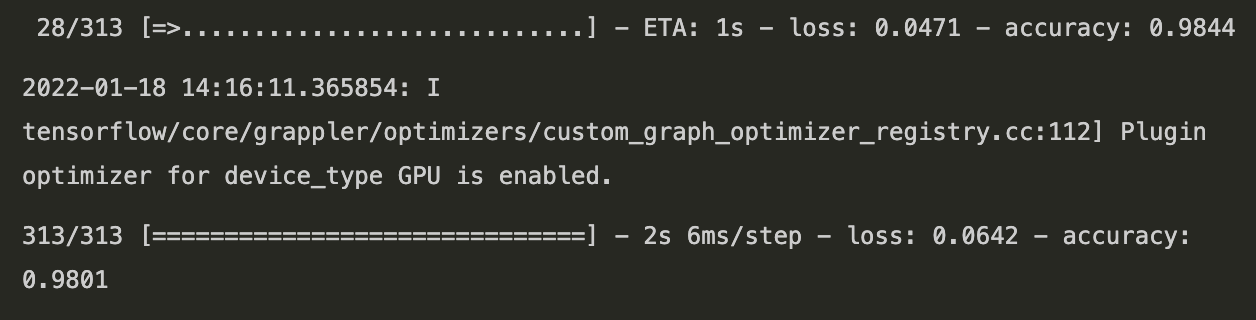
0.9801 정도 정확도가 나왔다.
1
2
# 모형 성능평가 결과값
print(f'test_loss:{test_loss}');print(f'test_acc:{test_acc}')
test_loss:0.06420930474996567
test_acc:0.9801000356674194
학습된 모형에 이미지 넣어보기
데이터셋 로드 - 훈련데이터 vs 검증데이터 나누기 - 모델 로드 - 모델 컴파일 - 데이터셋 전처리 - 모델 학습 - 성능검증
위 과정을 통해 학습된 모델을 얻었다.
이 모델에 임의의 MNIST 데이터 하나를 넣어서, 어떻게 분류해내는지 한번 보자.
1
2
# 임의의 MNIST 데이터
first_image = train_images[3].reshape((1,28*28))
훈련용 셋에서 3번째 이미지 데이터를 빼냈다. 그리고 이걸 행벡터 형태로 변환했다.
그 후 모형의 predict() 메소드에 넣어서 3번째 이미지를 분류하도록 했다.
1
2
result = network.predict(first_image)[0]
result # 소프트맥스 함수 출력값
결과:
1
2
3
array([2.3608993e-09, 9.9996030e-01, 1.2336987e-05, 8.0996138e-08,
1.6119817e-06, 1.2742596e-08, 2.0098611e-08, 1.7875993e-05,
7.7193372e-06, 4.1783554e-09], dtype=float32)
결과는 소프트맥스 함수 출력값. 즉 확률 꼴 값이다. 각 값들은 0과 1사이 값이고, 총합은 1이다.
이 경우 result 값은 10차원 벡터로 나오고, 각 값들은 모형에 예측하도록 시킨 3번째 이미지가 각 카테고리값일 확률을 나타낸다.
위 출력값을 좀 더 이해하기 쉽게 시각화했다.
1
2
3
4
5
6
7
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(5,2))
sns.barplot(list(range(0,10)), result)
plt.title('prediction result')
plt.show()

seaborn을 이용해 막대그래프로 각 카테고리값 별 확률을 나타냈다.
모델은 3번째 이미지를 ‘1’ 로 예측했음을 볼 수 있다.
그러면 1로 분류된 3번째 이미지가 실제로 어떤 형상이었는지, 직접 육안으로 확인하자.
1
2
3
4
plt.figure(figsize=(1,1))
plt.imshow(train_images[3].reshape(28,28))
plt.axis('off')
plt.show() # 모델이 1로 분류해냈다.

사람인 내가 봐도 이 숫자는 1인것 같다.
모델이 제대로 잘 분류해냈음을 관찰할 수 있었다.