
글 원본 : https://blog.naver.com/tigerkey10/222333877000
이 글은 내가 지킬 블로그를 만들기 전,
네이버 블로그에 공부 내용을 기록할 때 PCA 주성분분석을 처음 학습하고 복습하면서 기록했던 두번째 글을 옮겨온 것이다.
네이버 블로그에서 글을 옮겨와 지킬 블로그에도 기록해둔다.
모든 공부 과정을 기록으로 남겨 치열했던 시간들을 기록으로 남기고,
미래에 전달해 스스로 동기부여할 것이다. 또한 반복해서 학습. 복습하는 과정에서
어떤 개념에 대한 내 이해가 어떻게 변화.발전 했는지 관찰함으로써 스스로의 학습 정도를 돌아보는 거울로 삼고자 한다.
아래 글은 ‘김도형의 데이터사이언스 스쿨 - 수학편(한빛미디어)’ 수업을 듣고,
공부한 내용을 토대로 복습. 이해한 내용을 제 언어로 다시 기록한 글 입니다.
PCA를 정확히 이해하고, 데이터분석에 활용하기 위해 다시 재복습. 실습한 내용을 기록한다.
PCA의 쓸모
-
1개 레코드 안에서 데이터 변이 원인 파악 가능 <– 어떤 주성분이 뒤에 있나? 파악가능
-
여러 레코드 간 데이터 다르게 나타나는 이유 파악 <– 주성분이 어떻게 다르게 작용하나? 파악가능
직관적 이해 : 고차원 데이터를 ‘분해’ 해서 변화시키는 핵심 인자만 뽑아낼 수 있다
- 노이즈 날리고, 공통부분(데이터 평균) 날리고, 해당 데이터 벡터를 구성.규정하는, 다른것들과 다르게 만드는 핵심인자인 주성분만 남긴다
로우-랭크 근사 문제로 PCA를 이해하면
-
‘고차원 데이터의 투영벡터 만들어주는 저차원 공간의 기저벡터를 찾아라’가 PCA의 목표다.
-
그 기저벡터가 바로 주성분이다.
-
그 기저벡터는 투영벡터 만들어야 하니까 당연히 원래 고차원 벡터랑 같은 차원의 벡터다.
-
투영벡터를 좌표변환한 값이 우리가 찾은 차원축소 결과물이다.
붓꽃 데이터 PCA 수행하기
- 차원축소 : 1차원(전체 데이터 설명하는 주성분 1개 찾겠다)
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
X = load_iris()
X1 = X.data #고차원 데이터
X1

데이터 간 다르게 만드는 요인, 그리고 1개 데이터레코드 내부에서 각 스칼라 일정 비율로 다르게 만드는 요인을 찾자.
-
1개 원인을 찾을 것이다.
-
1차원 차원축소 시켰다. 아래 1차원 벡터들은 원본 벡터를 평균제거벡터로 만든 뒤, 1차원 근사시켜서 주성분 만으로 구성한 것이다.
-
결과적으로 원본 데이터에 포함되어 있던 노이즈도 1차원 근사(1차원 벡터공간 상에 가장 비슷한 근삿값을 만들겠다)하면서 다 제거했다.
pca = PCA(n_components=1)
X_low = pca.fit_transform(X1)
df = pd.DataFrame(X_low).head(5)
df.rename(mapper={0:'꽃 크기 : 주성분 값'}, axis=1, inplace=True)
df

-
데이터프레임 각 행은 ‘주성분 값’이다.
-
저차원 데이터에서 주성분이 차지하는 비중을 나타내기도 한다.
-
위 1차원 벡터는 투영벡터 좌표변환 한 것이다.
-
아래 벡터가 저차원 데이터 구성하는 주성분이다.
-
아래 주성분 벡터의 의미는 ‘꽃 크기’이다.
pca.components_

위 1차원 벡터를 중심 원점으로 옮기고, 2차원 공간상으로 다시 역변환하면 아래와 같다
- 차원축소 결과물을 역변환한, 평균과 주성분으로 이루어진 원래 고차원 데이터의 근삿값이다.
print(pca.components_*(-2.684126)+pca.mean_)
print()
print(pca.inverse_transform(X_low)[0])

아래는 원본데이터 & 이것과 가장 비슷한 근삿값이다.
-
근삿값은 평균 + 주성분벡터 선형조합으로만 이루어져 있다.
-
결과적으로 원래 데이터와 가장 비슷하면서도, 노이즈 제거한 데이터 얻을 수 있었다.
print(X1[0])
print(pca.inverse_transform(X_low)[0]) #가장 비슷한 & 노이즈 제거된 데이터
-
주성분벡터(주성분)은 저차원 공간의 기저벡터다.
-
랭크-k 근사 문제에 따르면, 이 저차원 공간 기저벡터는 특징행렬 X의 특이벡터 M개 중 가장 큰 K개 특잇값에 대응되는 K개와 같다.
-
또는 이 행렬로 구성된 분산행렬의 가장 큰 K개 고윳값에 대응되는 K개 고유벡터와 같다.
# 증명해보자.
ld, V = np.linalg.eig((X1-pca.mean_).T@(X1-pca.mean_))
print(V[:,0])
U, sg, VT = np.linalg.svd(X1-pca.mean_)
print(VT.T[:,0])
print(pca.components_)

- 아래 저차원 데이터는 고차원 데이터의 투영벡터와도 같다.
X_low[7]

이제 아래 투영벡터를
((X1[7]-pca.mean_).T@pca.components_.T@pca.components_)

w = pca.components_
w

변환행렬 w를 곱해서
((X1[7]-pca.mean_).T@pca.components_.T@pca.components_)@w.T

저차원 공간 상의 좌표로 좌표변환한 것과 같다.
투영벡터는 당연히 저차원 공간의 기저벡터만으로 이루어질 것이다. 따라서 위 1차원 벡터는 주성분만으로 이루어진 저차원 데이터이다.
-2.62614497*w

주성분 값의 의미 : 원래 고차원 데이터에 주성분이 들어있는 정도를 보여준다.
-
예) 붓꽃 : 8번 꽃 크기가 얼마인가? 나타낸다.
-
예) 올리베티 얼굴사진 : 3번 이미지에 웃는 표정 성분이 얼만큼 들어있나? 찡그린 표정 성분이 얼마나 들어있나? 나타낸다.
-
예) 주식 PCA : 한국 주식 연간 수익률 데이터에 중진국 요인이 얼마만큼 들어있나? 나타낸다.
올리베티 얼굴사진으로 PCA 수행해보자.
from sklearn.datasets import fetch_olivetti_faces
faces_all = fetch_olivetti_faces()
K = 9
faces = faces_all.images[faces_all.target==K]
N = 2
M = 5
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for i in range(N) :
for j in range(M) :
k = i*M+j
ax = fig.add_subplot(N, M, k+1)
ax.imshow(faces[k], cmap=plt.cm.bone)
ax.grid(False)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.suptitle('올리베티 얼굴사진')
plt.tight_layout()
plt.show()

각 이미지 구성하는 주성분을 3개로 뽑아내보자.
pca1 = PCA(n_components=3)
X_low = pca1.fit_transform(faces_all.data[faces_all.target==K])
df2 = pd.DataFrame(X_low)
df2.rename(mapper={0:'주성분1 값', 1:'주성분2 값',2:'주성분3 값'}, axis=1, inplace=True)
df2.head(3)
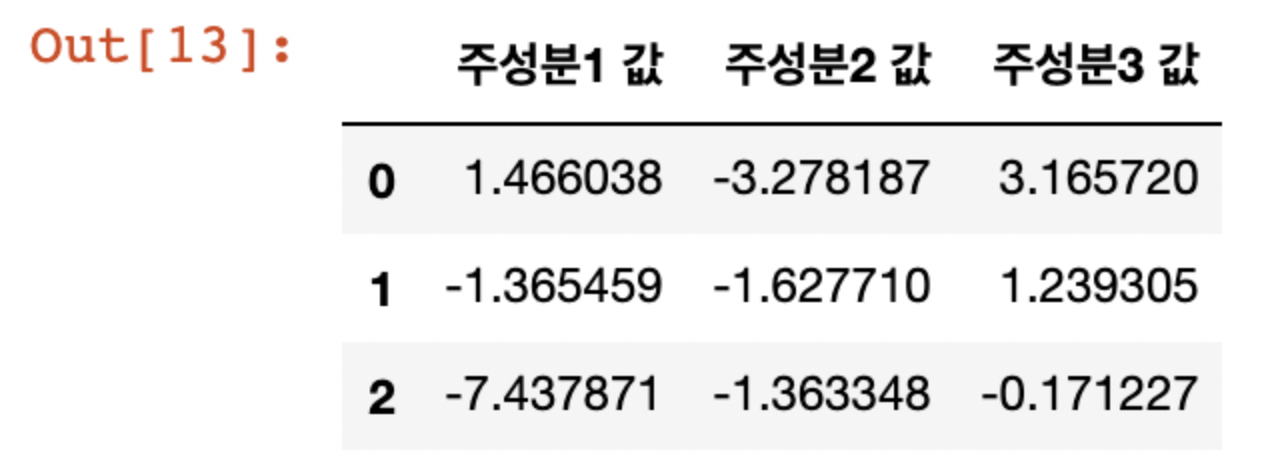
-
fit_transform() 메서드로 위 여자 사진을 주성분 만으로 구성했다.
-
1번 여자 사진은 주성분 3이 높고, 2가 낮은 비중 차지하고 있다.
-
2번 여자 사진 역시 주성분 3 비중이 높고, 주성분 2 비중이 상대적으로 낮다
-
3번 여자 사진은 주성분 1 비중이 극단적으로 낮고, 주성분 3이 상대적으로 높다.
-
추정컨대 1번 주성분은 얼굴 방향과 관련 있는 듯 하고, 주성분 3은 미소 여부와 관련있는듯 하다
위 주성분의 의미를 찾아보자.
face_mean = pca1.mean_.reshape(64,64) #평균얼굴(모든 데이터의 공통요소)
face_p1 = pca1.components_[0].reshape(64,64) #첫번째 주성분
face_p2 = pca1.components_[1].reshape(64,64) #두번째 주성분
face_p3 = pca1.components_[2].reshape(64,64) #세번째 주성분
plt.subplot(141)
plt.imshow(face_mean, plt.cm.bone)
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.title('평균얼굴')
plt.subplot(142)
plt.imshow(face_p1, plt.cm.bone)
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.title('주성분 1')
plt.subplot(143)
plt.imshow(face_p2, plt.cm.bone)
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.title('주성분 2')
plt.subplot(144)
plt.imshow(face_p3, plt.cm.bone)
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.title('주성분 3')
plt.show()

-
평균 얼굴과 주성분 1~3을 찾았다. 각 주성분을 아이겐페이스라고 하기도 한다.
-
아래 원본 근사벡터는 평균 + 주성분 1~3 선형조합 한 것과 같다.
X22 = pca1.inverse_transform(X_low)
print(X22[0])
print(pca1.mean_+(1.4660367*pca1.components_[0])+(-3.2781866*pca1.components_[1])+(3.1657133*pca1.components_[2]))
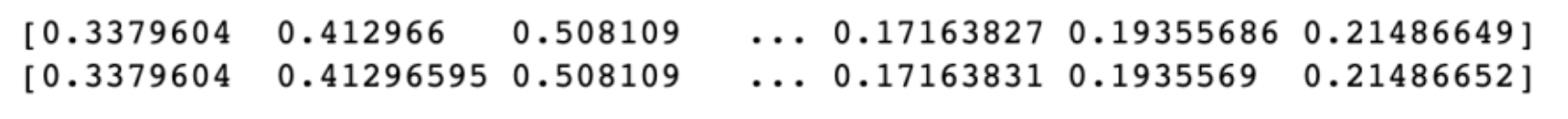
각 주성분의 의미를 이미지로 좀 더 쉽게 알아보자.
N = 2
M = 5
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for i in range(N) :
for j in range(M) :
k = i*M+j
ax = fig.add_subplot(N, M, k+1)
w = 1.5*(k-5)if k < 5 else 1.5 *(k-4)
ax.imshow(face_mean + w * face_p1, cmap=plt.cm.bone)
ax.grid(False)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.title('주성분 1의 비중 %s' %w)
plt.suptitle('평균 얼굴 + 주성분 1')
plt.show()

예상이 맞았다. 1번 주성분은 얼굴 방향을 결정짓는 주성분이었다.
N = 2
M = 5
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for i in range(N) :
for j in range(M) :
k = i*M+j
ax = fig.add_subplot(N, M, k+1)
w = 1.5*(k-5)if k < 5 else 1.5 *(k-4)
ax.imshow(face_mean + w * face_p2, cmap=plt.cm.bone)
ax.grid(False)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.title('주성분 2의 비중 %s' %w)
plt.suptitle('평균 얼굴 + 주성분 2')
plt.show()

-
2번 주성분은 인물의 시선을 결정짓는 주성분이다.
-
주성분 비중이 높아질수록 여성은 정면을 바라보고, 주성분 비중이 낮아질 수록 여성은 오른쪽을 바라본다.
N = 2
M = 5
fig = plt.figure(figsize=(10,5))
plt.subplots_adjust(top=1, bottom=0, hspace=0, wspace=0.05)
for i in range(N) :
for j in range(M) :
k = i*M+j
ax = fig.add_subplot(N, M, k+1)
w = 1.5*(k-5)if k < 5 else 1.5 *(k-4)
ax.imshow(face_mean + w * face_p3, cmap=plt.cm.bone)
ax.grid(False)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.title('주성분 3의 비중 %s' %w)
plt.suptitle('평균 얼굴 + 주성분 3')
plt.show()

예상대로 3번 주성분은 미소 여부를 결정짓는 주성분이었다.
- 3번 주성분 비중이 낮아지면 미소가 사라지고, 3번 주성분 비중이 높아지면 인물이 미소짓고 있는 걸 볼 수 있다.
주식가격 PCA 수행하기
pd.core.common.is_list_like = pd.api.types.is_list_like
import pandas_datareader.data as web
import datetime
symbols = [
'SPASTT01USM661N',
'SPASTT01JPM661N',
'SPASTT01EZM661N',
'SPASTT01KRM661N',
]
data = pd.DataFrame()
for sym in symbols :
data[sym] = web.DataReader(sym, data_source='fred',
start=datetime.datetime(2001, 1,1),
end=datetime.datetime(2020, 12,31))[sym]
data.columns=['US', 'JP', 'EZ', 'KR']
data = data / data.iloc[0]*100
styles = ['b-.','g--', 'c:','r-']
data.plot(style=styles)
plt.title('세계 주요국 20년간 주가')
plt.show()

df = ((data.pct_change() +1).resample('A').prod()-1).T * 100
print(df.iloc[:,:6])
df

-
각 데이터레코드 배후에는 레코드 내부 측정치들 간 차이를 결정짓는 잠재변수가 있을 것이다.
-
각 데이터레코드 별로 차이를 결정짓는 잠재변수가 있을 것이다. 이 특정 주성분이 얼마나 포함되었느냐에 따라 나라별 주가 움직임이 달라질 것이다.
df.T.plot(style=styles)
plt.title('주요국 과거 20년간 연간 수익률')
plt.xticks(df.columns)
plt.show()

각 데이터 양상을 결정짓는 주성분이 뒤에 있다.
- 연도별 수익률 비율이 이미 정해져 있다는 뜻이고, 그래서 각 그래프 모양이 대략 비슷하게 나타나는 거다.
PCA 수행해서 어떤 주성분이 각국 주가 움직임 구성하고 있는지 보자.
- 각 국 주성분 비중부터 보자.
from sklearn.decomposition import PCA
pca3 = PCA(n_components=1)
X_low = pca3.fit_transform(df) #고차원 데이터 투입
stock_mean = pca3.mean_
transformed_df = pd.DataFrame(X_low)
transformed_df.index = ['US', 'JP', 'EZ', 'KR']
-
아래 행렬은 각 데이터의 주성분 비중을 보여준다.
-
한국이 주성분 비중이 가장 높고, 미국이 주성분 비중 가장 낮다
-
이 주성분은 한국에 가장 큰 영향 미치는 주성분이다.
transformed_df

주성분은 아래와 같다.
p1 = pca3.components_[0]
p1

X33 = pca3.inverse_transform(X_low)
df_i = pd.DataFrame(X33)
df_i.index = df.index
df_i.columns = df.columns
df_i.iloc[:, -10:]
df_i.T.plot(style=styles)
plt.title('주성분과 공통요소만으로 구성된 주요국 과거 20년간 연간 수익률 근사치')
plt.xticks(df.columns)
plt.show()

-
한국이 3국 공통에서 다소 조금씩 벗어나는데, 주성분이 크게 작용해서 그렇다.
-
한국을 선진국 3개국 데이터에서 벗어나게 만드는 주성분은 뭘까?
이 주성분 의미를 알아보자.
주성분이 양의 방향으로 추가될 때
xrange = np.linspace(2001, 2020, 20, dtype=int)
for i in np.linspace(0, 100, 5) :
plt.plot(xrange, pca3.mean_+p1*i)
plt.plot(xrange, pca3.mean_+p1*100, label='주성분 100배 추가한 수익률')
plt.plot(xrange, pca3.mean_, 'ko-', lw=5, label='평균 수익률')
plt.title('주성분 양의 방향으로 추가될 때 주가수익률 변화')
plt.legend()
plt.show()

주성분이 음의 방향으로 추가될 때
xrange = np.linspace(2001, 2020, 20, dtype=int)
for i in np.linspace(-100, 0, 5) :
plt.plot(xrange, pca3.mean_+p1*i)
plt.plot(xrange, pca3.mean_+(p1*-100), label='주성분 100배 추가한 수익률')
plt.plot(xrange, pca3.mean_, 'ko-', lw=5, label='평균 수익률')
plt.title('주성분 음의 방향으로 추가될 때 주가수익률 변화')
plt.legend()
plt.show()

-
이 주성분 비중이 양의 방향으로 커질수록 데이터가 공통수준에서 양의 방향으로 멀어진다.
-
한국에 가장 크게 양의 방향으로 작용하는 주성분이다. 나머지 국가는 마이너스다.–> 공통수준에서 음의 방향으로 떨어진다
-
한국만 다른 3개국 수준에서 벗어나게 하는 주성분이다.
-
한국을 다른 3개국으로부터 멀어지게 만드는 주성분이다.
-
다른 3개국 공통점 : 선진국
-
한국을 선진국 수준으로부터 멀어지게 만드는 주성분이다.
-
한국을 중진국에 머물게 하는 요소다.
-
주성분은 ‘중진국 요인’이다.
-
한국의 주가 그래프가 다른 3개국과 다른 양상으로 변화하는 것은 중진국 요인이 있기 때문이다.
이 주성분이 양의 방향으로 많이 작용할수록
그래프가 일본, 유럽, 미국 쪽에서 한국 쪽으로 변화한다.
- 한국 방향으로 그래프를 변화시키는 요인 : 중진국 요인이다.