
글 원본 : https://blog.naver.com/tigerkey10/222271388763
이 글은 내가 지킬 블로그를 만들기 전,
네이버 블로그에 공부 내용을 기록할 때 학습하고 복습하면서 기록했던 글을 옮겨온 것이다.
네이버 블로그에서 글을 옮겨와 지킬 블로그에도 기록해둔다.
모든 공부 과정을 기록으로 남겨 치열했던 시간들을 기록으로 남기고,
미래에 전달해 스스로 동기부여할 것이다. 또한 반복해서 학습. 복습하는 과정에서
어떤 개념에 대한 내 이해가 어떻게 변화.발전 했는지 관찰함으로써 스스로의 학습 정도를 돌아보는 거울로 삼고자 한다.
어떤 데이터도 전처리하고, 재구성 할 수 있는 데이터 분석가가 되기 위해 판다스 라이브러리 이용법을 훈련하고 있다.
판다스 라이브러리는 데이터프레임 분석, 데이터프레임 재구성, plot을 통한 그래프 생성 등등 데이터 전처리 및 분석에 유용한
많은 도구를 제공하는 좋은 라이브러리다. 훈련을 통해 좀 더 빠르고 능수능란한 데이터 분석 능력을 갖고자 한다.
물론, 라이브러리 이용에 과다하게 의존하면 안 된다고 생각한다. 본질은 확률 및 통계이론에 대한 지식 및 응용 능력,
데이터 셋 구성에 대한 이해, 각 데이터 간 관계에 대한 이해, 각 자료구조형에 대한 이해, 그리고 무엇이 깔끔한 데이터(tidy data)인지에 대한
이해와 응용이라고 생각한다. 이 훈련은 어떻게 하면 좀 더 기본 베이스 개념들을 더 빠르고 수월하게 적용할 수 있을까에 대한 답이라고 생각한다.
이번 훈련에는 pivot과 concat이라는 중요한 메소드 두 개 사용법 및 응용을 연습했다.
내가 공부하고 정의내린 Pivot()
-
칼럼, 인덱스, value 세 argument를 지정해줘야 한다.
-
서로 다른 case간에 만약 칼럼과 인덱스 동시에 고려한 key값이 같은 항(중복항)이 있을 경우, 피벗할 수 없다.
-
피벗은 조건부 확률이다.
-
칼럼, 인덱스가 주어졌을 때 이를 동시에 만족하는 value를 데이터프레임에 넣는다.
- 수행 순서는 다음과 같다.
-
지정된 칼럼 배열(칼럼 값들 중 중복 값들은 제외)
-
지정된 인덱스 배열(인덱스 값들 중 중복 값들은 제외)
-
1,2 동시에 고려한 key 조건을 만족하는 value값들 데이터프레임에 채워넣는다.
실전 예제를 통해 데이터프레임을 생성하는 연습 및 피벗 시키는 연습을 함께 해 보았다.
웹상에서 멀티 인덱스 표 예제 이미지를 구글링해서 찾은 뒤 따라 만들어보며 연습 예제로 삼았다.
내가 찾은 표는 K-data 한국데이터산업진흥원에서 만든 표로, 데이터기술동향< 정보마당 < 한국데이터산업진흥원 에 개제된 표이다.
https://kdata.or.kr/info/info_04_view.html?field=&keyword=&type=techreport&page=213&dbnum=127706&mode=detail&type=techreport
https://www.google.com/search?q=%EB%A9%80%ED%8B%B0+%EC%9D%B8%EB%8D%B1%EC%8A%A4+%ED%91%9C+%EC%98%88%EC%8B%9C&rlz=1C5CHFA_enKR834KR835&sxsrf=ALeKk016fdisfpxryBLnWrEzvFk8mjAyug:1615343489507&tbm=isch&source=iu&ictx=1&fir=20eX7HNFSYd3aM%252CazyiFbdQ4qCd2M%252C_&vet=1&usg=AI4_-kRW0SLNuxSI5TL8W13-EiftOZ9sog&sa=X&ved=2ahUKEwj-l4e316TvAhURyYsBHSGJBsgQ9QF6BAgcEAE#imgrc=20eX7HNFSYd3aM
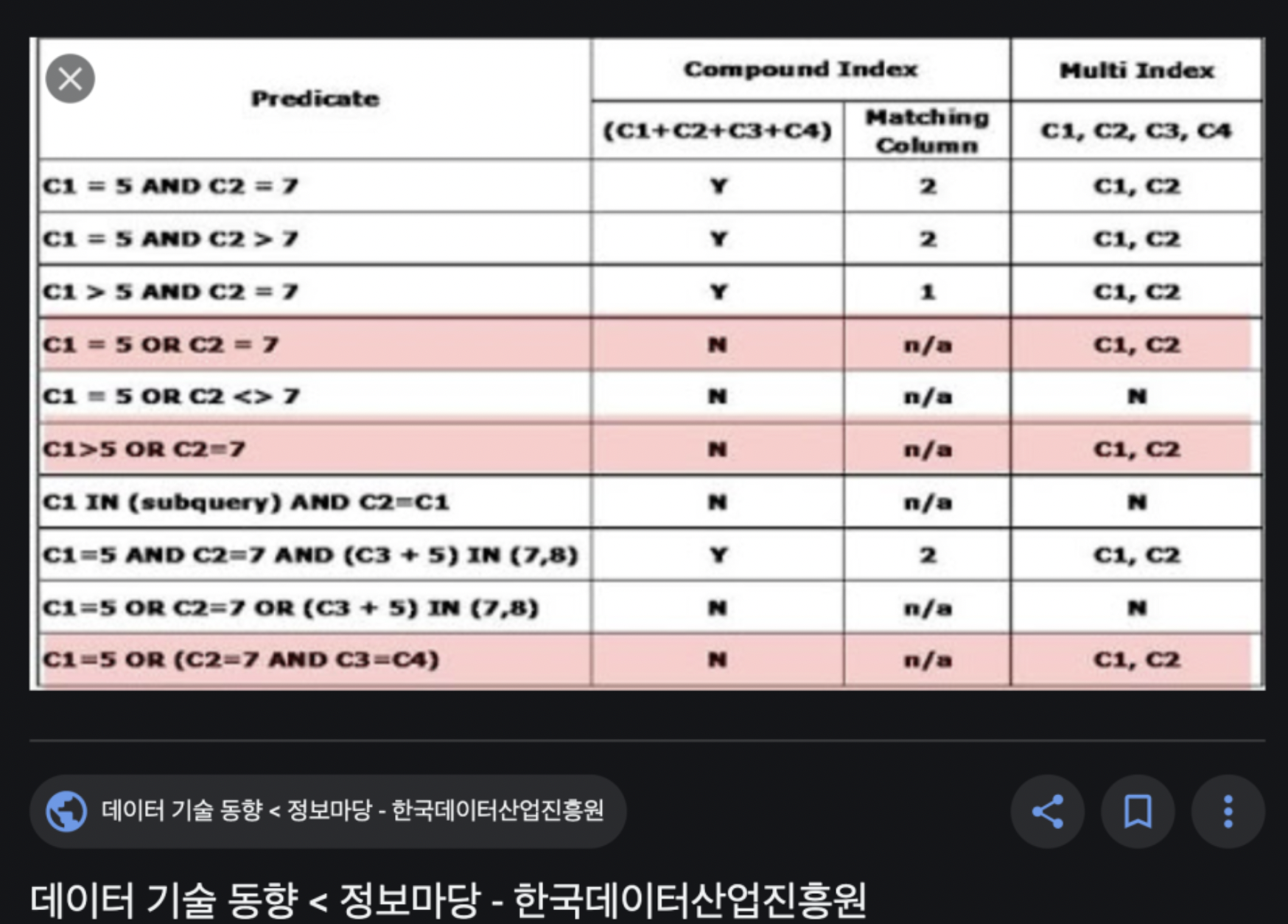
이 표를 보고, 데이터프레임을 생성한 후 피벗시켜보았다.
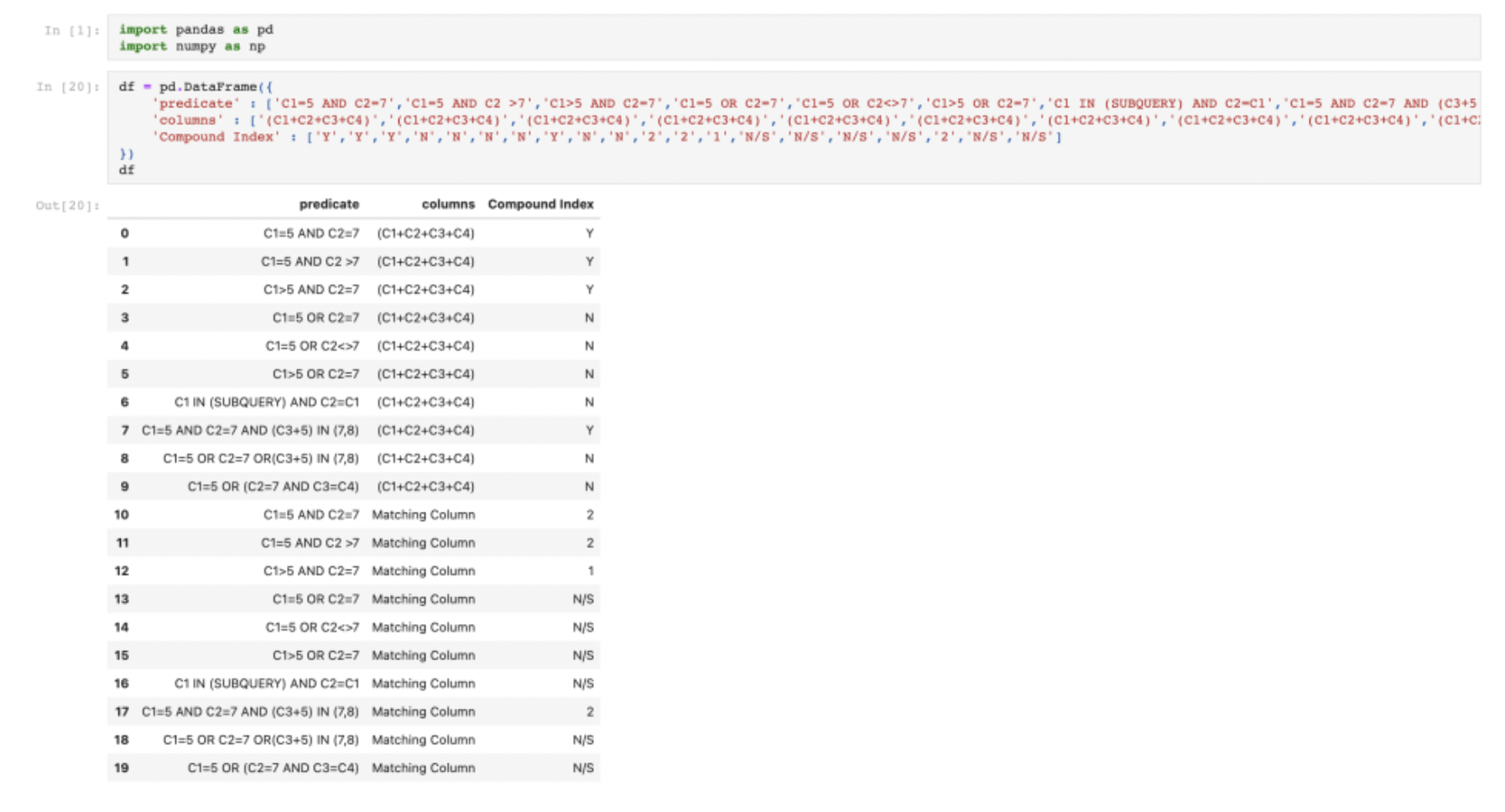
pd.DataFrame()으로 위 표를 그대로 생성할 수도 있을 것이다. 이게 더 쉬운 길 일수도 있다.
근데 쉬우면 재미 없잖나. 좀 더 돌아가기로 했다. 위 이미지 표를 생성할 수 있는 1단계 표를 하나 만들고,
공부한 피벗 메소드를 활용해서 위 이미지 표로 바꿔보기로 했다. 우선 이미지 상에 나온 표를 만들기 위해서는
두 개의 데이터프레임을 각각 생성해야 한다. (C1+C2+C3+C4)와 Matching Column 칼럼의 value값들은 모두
Compound Index라는 동일한 하나의 attribute으로 합칠 수 있지만, C1,C2,C3,C4칼럼은 Multi Index attribute에 속하기 때문이다.
따라서 Compound Index라는 칼럼으로 20개의 row를 갖춘 데이터프레임 하나, 그리고 Multi Index 라는 칼럼으로 10개 row 갖춘
데이터프레임 하나를 생성해야 한다.
Predicate라는 칼럼은 두 데이터프레임 모두 동일하게 포함되지만, Compound Index가 포함된 데이터프레임에서는 10개/10개로
동일한 내용을 두번 반복해야 한다. (C1+C2+C3+C4)칼럼과 Matching Column 칼럼 모두 동일한 인덱스를 갖고 있기 때문에,
두 칼럼을 일렬로 합칠 경우 동일한 인덱스를 두번 반복해야 한다.
이 같은 생각을 바탕으로 첫번째 데이터프레임을 생성하면 위와 같다.
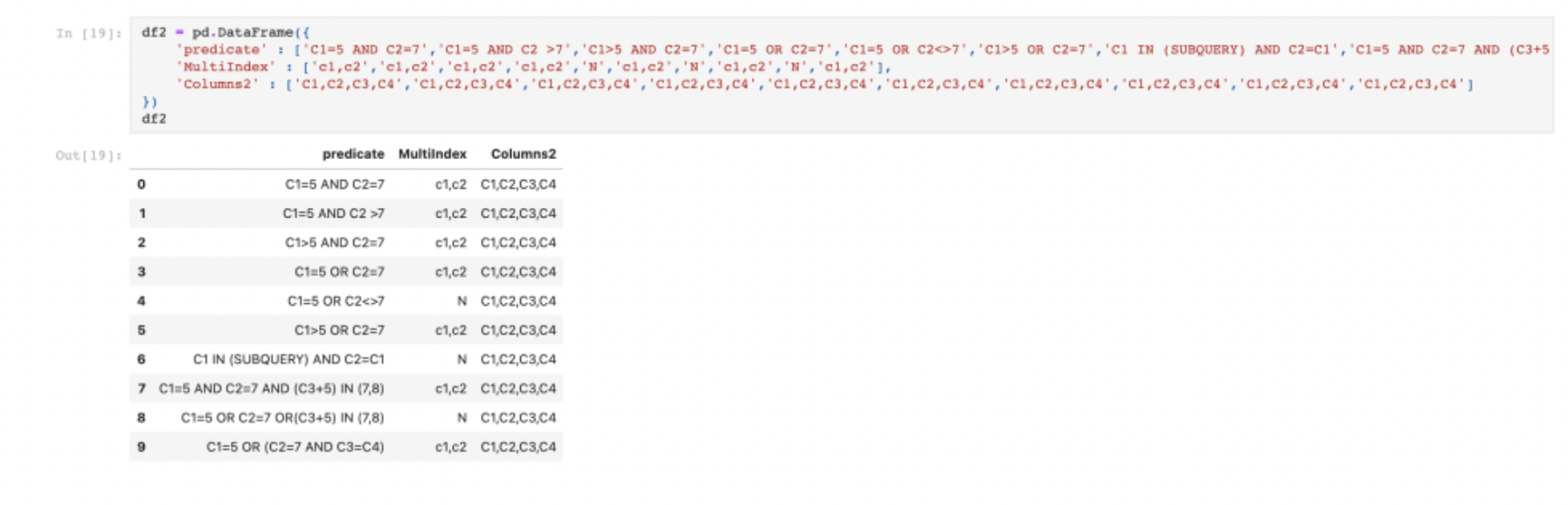
위 사진은 두 번째 데이터프레임을 생성한 것이다.
그리고 이제 두 데이터프레임을 각각 피벗시켜줘야 한다.
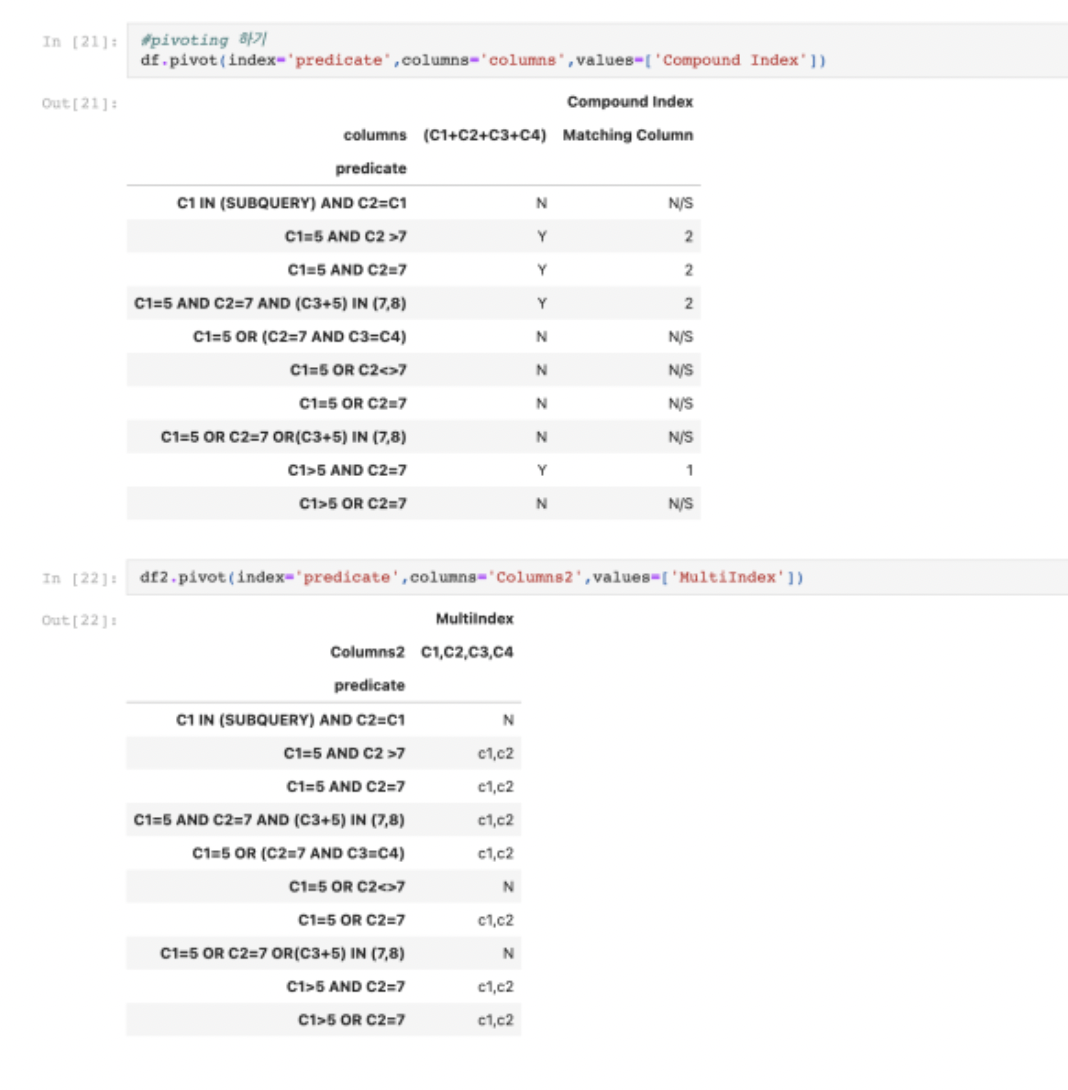
피벗하면 위 두 사진과 같다. 원래 표와 같은데, 두개로 쪼개진 데이터프레임임을 알 수 있다.
이제 그러면 두 데이터프레임을 합치면, 원래 표와 같은 결과가 나올 것이다.

내가 공부하고 정의내린 Concat()
-
concat은 데이터프레임을 합치게 해준다.(merge와는 다소 다르다)
-
합칠 때 조건을 outer join으로 해주면 두 데이터프레임의 합집합이 나온다.
-
합칠 때 조건을 inner join으로 해주면 두 데이터프레임의 교집합이 나온다.
-
두 데이터프레임 합쳤을 때 크기가 안 맞는 부분은 Null로 채워진다.
-
axis : 합치는 축을 지정해줄 수 있다. 0이면 행을 추가해서 합쳐줄 것이고(아래쪽에 붙인다) 1이면 칼럼을 추가해서 붙여줄 것이다
(왼쪽에 붙는다)
- keys : 각 개체를 구별지어주는 인덱스를 가장 바깥쪽 인덱스로 생성해준다. 이를 계층적 인덱스라고 부른다.axis=1로 합쳤으면
칼럼 쪽에 인덱스가 붙을 것이고, axis=0이면 row 쪽에 인덱스가 붙을 것이다. 이때 이 인덱스는 0,1 뿐 아니라 문자열로 지정해줄 수 있다.
- verify integrity : 만약 verify integrity = True로 설정하면 concat 시켜준 axis에 중복값이 있는지 보고, 중복이 있으면 Error를 발생시켜서
concat을 못하게 한다.
-
ignore index : Ignore index=True이면 concat할 때 지정해준 axis에 부여된 기존 인덱스 값들을 모두 날려버리고, 0부터 시작하는 기본 인덱스로 바꿔준다.
-
names : names를 통해 멀티 인덱스 각 인덱스 순서에 이름을 지정해줄 수 있다.
-
sort : axis=1일 때는 0번 축을, axis=0일 때는 1번 축을 오름차순 정렬해준다
axis부터 sort는 argument로, 각각 기본값이 지정되어 있고, 내가 변경해줄 수 있는 값들이다.
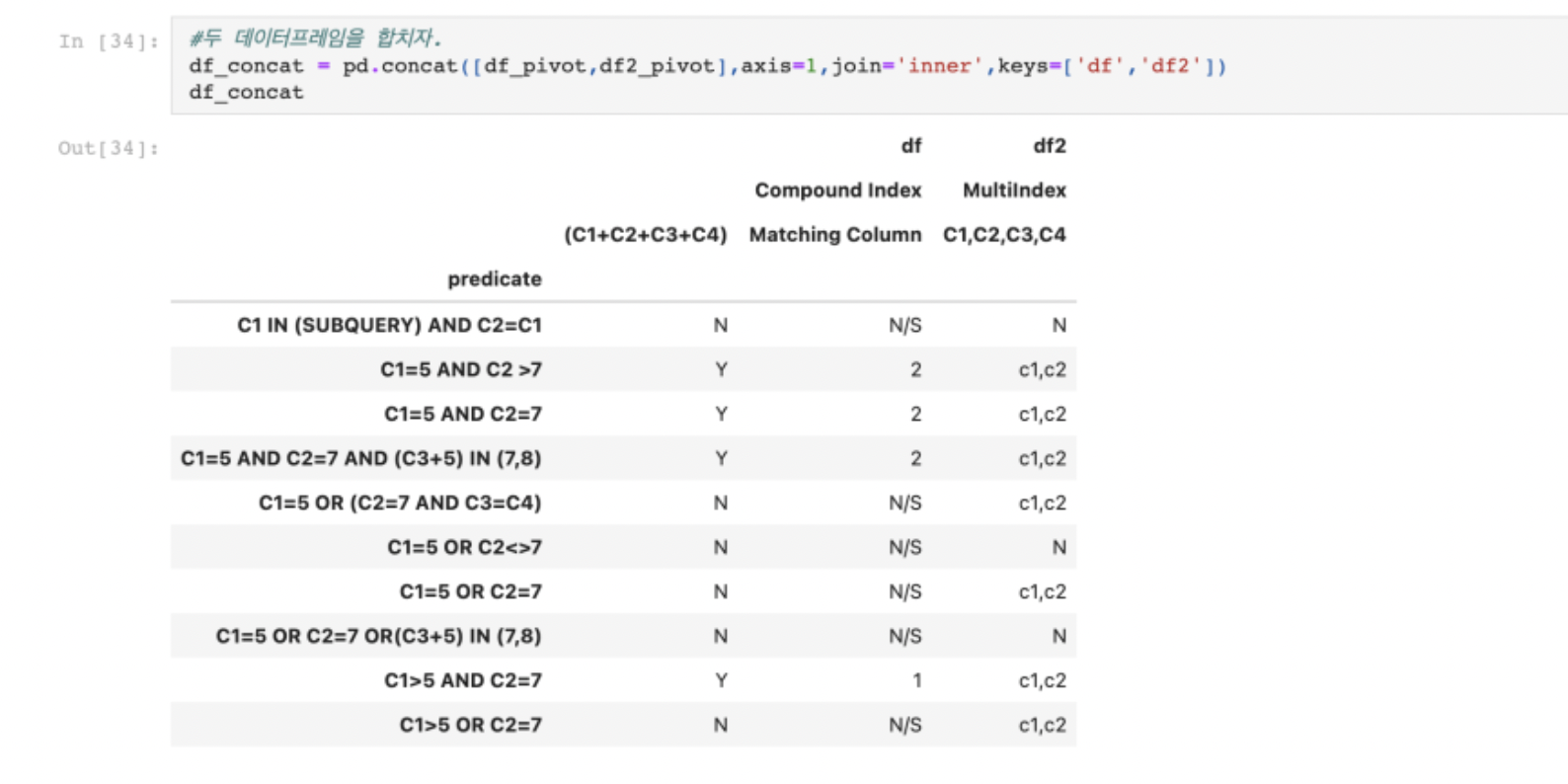
concat() 을 통해 이전 과정에서 만들어준 두 데이터프레임을 합치면 위 이미지와 같다.
이 같이 데이터프레임에 pivot()과 concat()을 이용해 데이터프레임을 조작하고, 합쳐서 내가 원하는 데이터프레임을 생성할 수 있었다.